When Performance is Irrelevant (Part 4)
Posted by Mark on April 27, 2017 at 07:11 | Last modified: November 22, 2016 10:37The motivation for this blog mini-series stems from an article on “robo-advisers” by Jaclyn N. McClellan in the Oct 2016 AAII Journal. With regard to performance comparison, she writes:
> A major question many investors ask is, “How
> does the performance of the robo-advisers
> compare to that of traditional advisers?”
> This is not a question that is easy to answer.
>
> Most of the robo advisory services that post
> performance online display backtested or model-
> based results…
That may be inaccurate because live-trading execution can significantly differ from backtesting (or based on models). They would need to present the research methodology (examples given here and here), which is usually not done.
> Each robo-adviser has different inception
> dates, and some don’t disclose those dates.
This is also true with regard to mutual funds, which makes it very difficult to pick up one prospectus and compare with another. Not giving the inception date seems absurd.
> Prospective clients have to search for the
> performance disclosures just to read the fine
> print…
This is consistent with the mutual fund prospectus. None of this is straight-up, transparent disclosure although I’m sure their compliance departments would claim to be meeting regulatory standards.
> Although the lack of sound performance figures
> may seem disheartening, displaying truly
> representative returns is difficult because
> many investors have customized portfolios—
> fees, allocations and rebalancing intervals can all
> be different on an account-by-account basis.
> Clients open accounts at different times, so
> even if the respective risk/reward profile
> categories don’t change, the starting value will.
The countless number of potential permutations of an investment account is another reason why it seems inappropriate to use a single historical record to measure performance.
An alternative to showing a single number for 1-year (5-year) performance, for example, would be to show a distribution of rolling 1-year (5-year) performance records. A fund that has been around for two (10) years has roughly 252 (1,260) rolling 1-year (5-year) periods that may be sampled. I could then look at the mean, standard deviation, and percentiles to make good sense out of these numbers, which constitute a much more robust sample size.
I will continue next time.
Categories: Financial Literacy | Comments (0) | PermalinkWhen Performance is Irrelevant (Part 3)
Posted by Mark on April 24, 2017 at 07:32 | Last modified: November 22, 2016 09:48In this blog mini-series I’m considering the possibility that financial performance reporting is at least misleading and at most irrelevant. As a third example, today I will discuss a prospectus for the T. Rowe Price Value fund.
First, take a look at the following table:
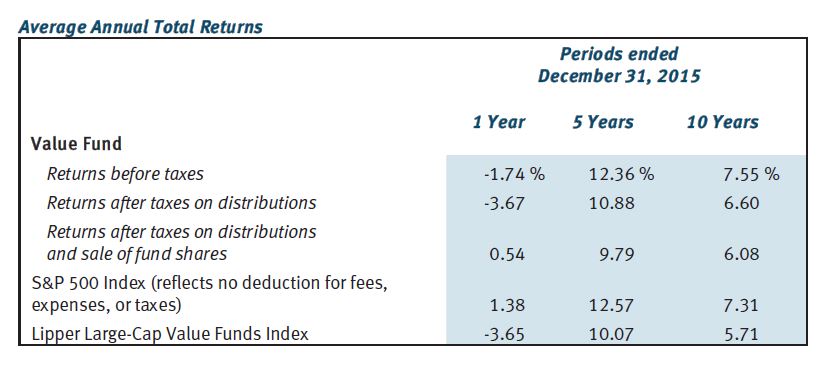
This gives us something against which to compare the fund’s performance. The Value Fund outpaced S&P 500 over 10 years but fell short over one and five. Value Fund beat the benchmark (Lipper Large-Cap Value Funds Index) over all three time frames but operating expenses (0.81%) are not included. Your actual performance would therefore fall short of the numbers reported here.
Once again, why be deceptive? Why not provide a historically accurate report of how the fund performed?
The prospectus also includes the following graph:
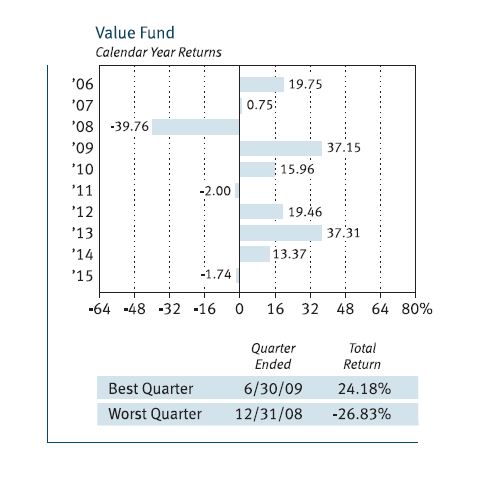
This gives us a 10-year track record to look at, which is better than the two years seen with American Funds Growth Portfolio. Ten is still a small sample size, though.
What may be worse is that each of the 10 samples is itself far too small a sample. I mentioned this with regard to the Vanguard prospectus: we do not see any error bars on the graph.
What happens in any particular calendar year is only one representation of an infinite number of potential occurrences. What if a large bankruptcy had been announced December 29 instead of January 5? What if Friday fell on the 31st instead of the 1st causing a jobs report to be delayed a week? What if a verbal misunderstanding, a dropped call, or a random muscle twitch had resulted in two countries going to war?
The fact that altered events can theoretically result in significant performance differences suggests just how trivial any single sample is. For me this is strong motivation for Monte Carlo simulation.
Monte Carlo simulation is a methodology used to generate large sample sizes. Given a system with many trades, toss the profit/loss numbers into a hat, mix thoroughly, and pick randomly to get different trade sequences. This can be done thousands of times. Robust descriptive statistics may then be used to generate and discuss probability-based future predictions of performance.
Monte Carlo simulation is unfortunately the exception—not the rule. Singular performance numbers based only on specific historical records are routinely reported. Laypeople in droves (along with their investment advisers) make frequent decisions based on these reports that, I would argue, are statistically meaningless.
This is a big reason why I suspect financial performance may be irrelevant.
Categories: Financial Literacy | Comments (0) | PermalinkWhen Performance is Irrelevant (Part 2)
Posted by Mark on April 21, 2017 at 06:19 | Last modified: November 18, 2016 10:26In this blog mini-series I’m considering the possibility that financial performance reporting is at least misleading and at most irrelevant.
Last time I briefly discussed a prospectus for a Vanguard fund. As a second example, let’s look at the American Funds Growth Portfolio prospectus:
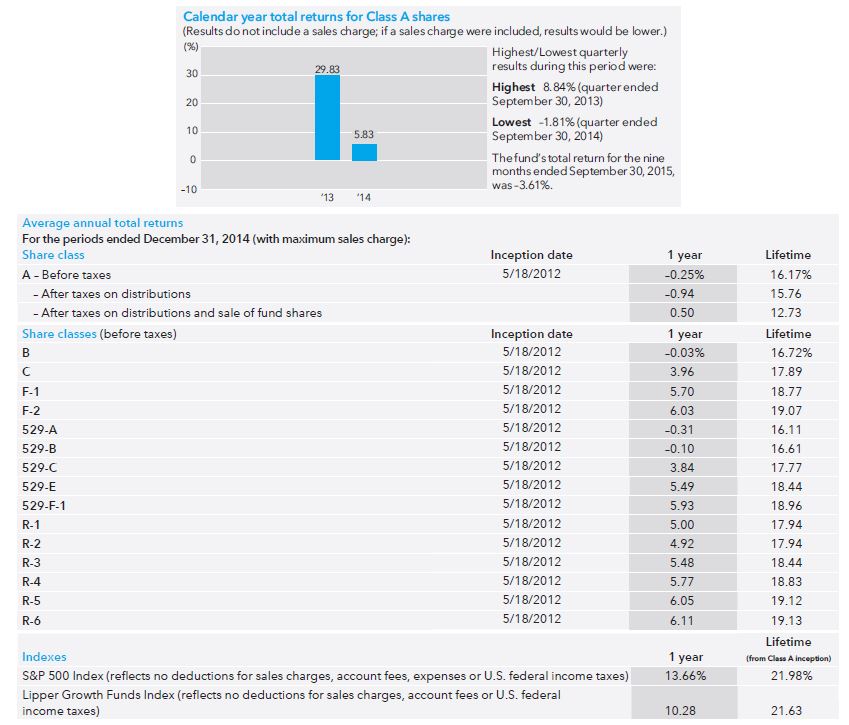
The first thing I noticed here is the short track record. The bar graph only shows performance for two years since the fund opened May 2012. Instead of 10 tiny samples (Vanguard), here we have two tiny samples.
An additional problem is a failure to include the sales charge. The disclaimer “if a sales charge were included, results would be lower” is nice but they don’t tell us how much lower it might be. I would like to see the maximum possible sales charge included as they did in the table. If the worst-case performance is acceptable then I’m more likely to invest. Either way, the point of a graph is to show and they failed to do that because what they graphed is not realistic.
The table indicates that every share class (of which there are many) underperformed the S&P 500 and the benchmark (Lipper Growth Funds Index). This is not encouraging but again, the sample size is sufficiently small here to mean very little. For a quick second I am happy that they at least included the sales charge.
But don’t think for more than a second that they reported the actual performance because other fees are not included. Evidently it does not pay to look only at the performance section because earlier in the prospectus we see:
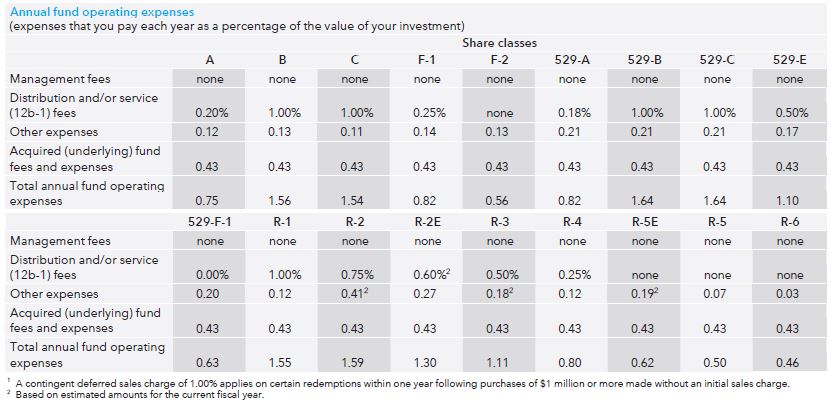
“Operating expenses” range from 0.46% – 1.64% annually. I called to get more information and only Class A and Class C shares are available to me as a prospective retail investor (“individual nonqualified account”). That means I would be stuck with a 0.75% annual fee on top of a 5.75% load (sales charge) and 1% redemption charge or a 1.54% annual fee with no load and a 1% redemption charge. Unfortunately neither annual fee nor redemption charge is included in the graphs or the tables, which means the reported performance numbers are optimistic exaggeration.
Is this deceptive advertising?
I will continue next time with one final example.
Categories: Financial Literacy | Comments (1) | PermalinkWhen Performance is Irrelevant (Part 1)
Posted by Mark on April 18, 2017 at 07:26 | Last modified: November 18, 2016 12:45Plenty of reasonable doubt suggests traditional reporting of financial performance is irrelevant and serves only to mislead.
I am not saying reporters of financial performance are aiming to mislead. This post is not categorized optionScam.com. Reporters may occasionally attempt to mislead but certainly not always. I also believe financial reporters often mean well and do exactly what their compliance teams require (e.g. for mutual funds or hedge funds). This can still fall short of the mark, however, which is why society as a whole needs increased levels of financial literacy.
I begin by taking a look at how investment performance is presented today. I did a search for “mutual fund prospectus” and took three hits from Google page 1. Let’s start with the Vanguard 500 Index Fund:
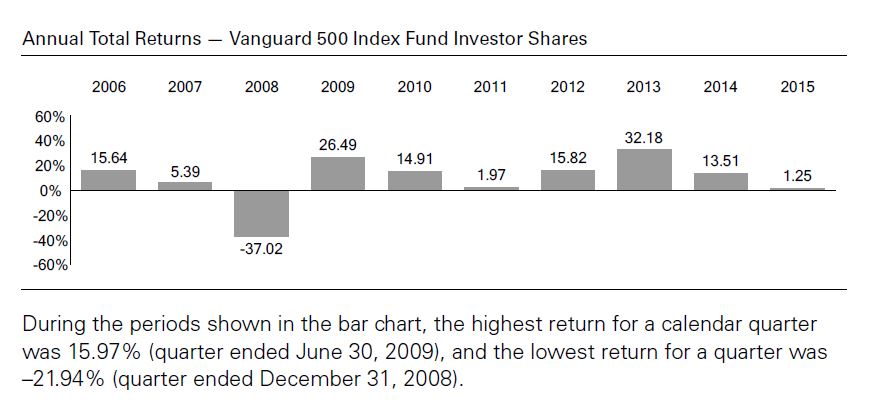
The main critique I have of these numbers is that each year includes only one sample. We don’t see any [standard] error [of the mean] bars here: each number is exactly what the fund returned during that calendar year. People tend to give samples created from a linear combination of historical data added weight and sometimes these historical samples (as opposed to simulated trials) are the only ones people recognize. Statistically speaking it is one and only one sample, however, which makes it the tiniest sample size available aside from zero. I had the same criticism for Craig Israelsen.
The prospectus also includes the following table:
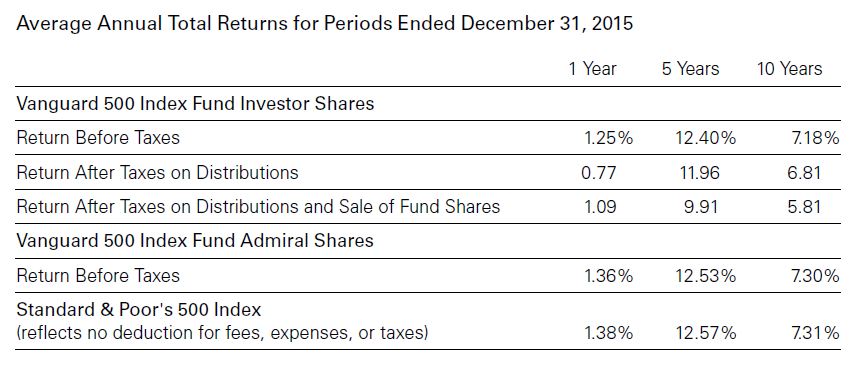
Nowhere does it state that transaction fees are included in the performance numbers. Transaction fees are mentioned in the last row where benchmark performance is given. While this may imply the fees are taken into account above, we cannot assume this.
I will make one tangential observation here about relative performance. The fund underperforms the benchmark for all three time frames whether looking at Investor Shares or Admiral Shares. Critics of actively managed funds sometimes emphasize large losing margins against the benchmarks. The only way to ever beat the benchmark is to actively invest. A passively managed fund is guaranteed to lose every time because of the fees—regardless of how small those fees might be.
I will continue with two more examples in the next post.
Categories: Financial Literacy | Comments (3) | PermalinkDynamic Iron Butterflies (Part 6)
Posted by Mark on April 4, 2017 at 06:42 | Last modified: May 26, 2017 12:53In the spirit of “who ever said making a business out of trading should be easy,” today I will present results on a 50% stop-loss (SL) applied to the dynamic iron butterfly (DIBF).
Backtesting this was actually not too difficult. Once I got started, it did not take much time to redo 526 backtrades. I did have to verify the cost of each trade because over the first few years of the data series, OptionVue had a lot of missing data (filling in with theoretical values is variable because it does so according to what data is in computer memory at that given moment). Thanks, as always, to Ken Dole for expert technical support when needed.
Here are some observations from redoing 526 backtrades:
–Nine trades came up winners
–Upon third check, only four of nine were winners
–Multiple trades would have been setup differently upon replication
These observations are due mostly to the inconsistencies described above. I did not change any backtrade results but I did remove four backtrades because the 50% SL was not triggered upon replication.
Here are some trade statistics with and without the SL:
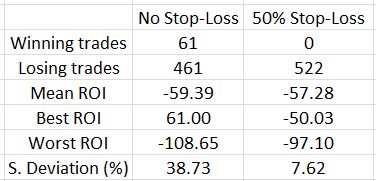
The 50% SL marginally improves results on average as the mean ROI improved 2.11% (all ROI’s are percentages).
Looking at the best and worst trades is an indication of how the range contracted with the SL. This is strongly affirmed by the standard deviation (SD), though, which becomes much smaller. Once again, SD is a measure of risk so this is meaningful.
How does this impact the overall backtest?
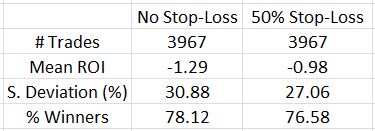
The SL improved the average trade by 0.31% and decreased the SD by over 10%. That’s definitely a win-win despite a lower number of losing trades.
One further thought I had about limiting losses was that the upside on an asymmetrical butterfly already has limited loss. If the SL is not implemented on the upside, trades that would otherwise go on to be winners would not be stopped out for losses. As it turned out, only eight of 61 trades that went on to hit the 10% profit target or went on to be profitable at expiration after being stopped out were hurt on the upside. Four of those butterflies were balanced, though. Not implementing the SL on market moves to the upside where the DIBF was asymmetrical only improved mean ROI by 0.5%. It also increased SD to 9.60%.
Although it did not improve trade statistics much (or at all), I think it makes sense to not implement an upside SL on an asymmetrical DIBF.
Categories: Backtesting | Comments (0) | Permalink