Understanding the Python Zip() Method (Part 1)
Posted by Mark on May 31, 2022 at 06:44 | Last modified: March 28, 2022 17:39As promised at the end of my last post, I’ve done some digging with some extremely helpful people at Python.org. Today I will work to wrap up loose ends mainly by discussing the Python zip() method.
My first burning question (Part 8) asks why L42 plots a line whereas L45 plots a point. The best answer I received says that matplotlib draws lines between points. If you give it X points then it will draw (X – 1) lines connecting those points. I was pretty much correct in realizing L45 receives one point at a time and therefore draws (1 – 1) = 0 lines.
To understand how L45 gets points, I need to better comprehend the zip() method. Zip() returns an iterator. Elements may then be unpacked via looping or through assignment.
Let’s look at the following examples to study the looping approach.
Unpacking to one variable (xp) outputs a tuple with each loop:
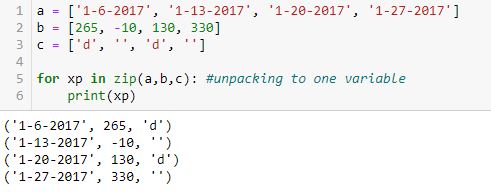
Unpacking to two variables (xp, yp) does not work:
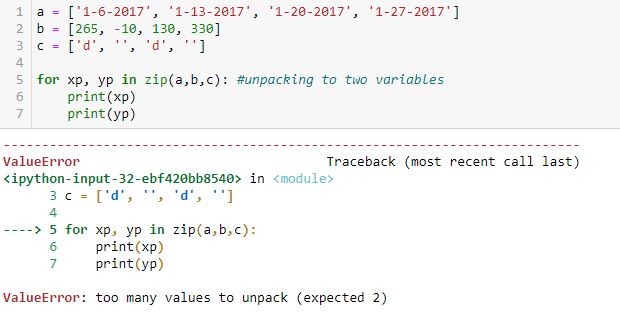
“Too many values to unpack” is confusing to me. If there are too many values to unpack for two variables, then why are there not too many to unpack for one? Perhaps the first example should be conceptualized as one sequence with four tuples. If so, then can’t this be conceptualized as one sequence with two tuples unpacked through two loops each?
Looping over the iterator with three variables yields this:
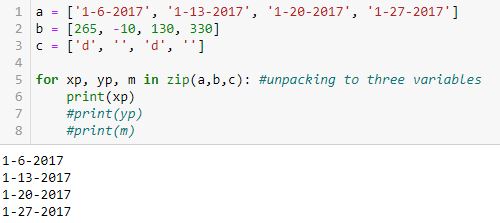
To better illustrate how the value from a gets assigned to xp, the value from b gets assigned to yp, and the value from c gets assigned to m, here is the same example with all variables printed:
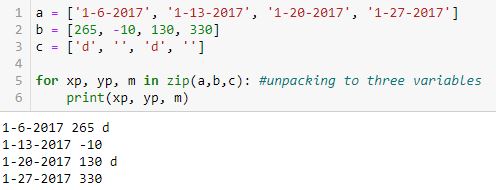
Unlike the top example, these are not tuples as no parentheses appear. Each line is just three values with spaces in between.
Looping over the iterator with four variables does not work:
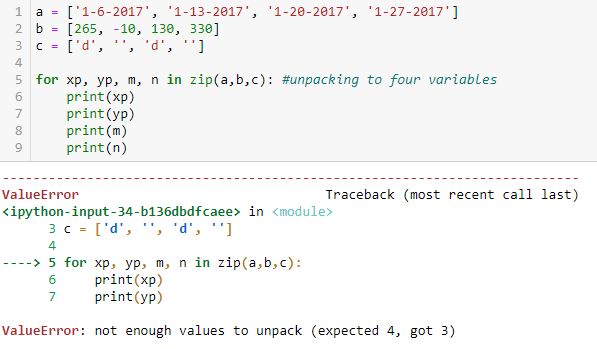
I understand why four were expected (xp, yp, m, n) and as shown in the previous example, only three lists are available to be unpacked up to a maximum of four times.
Next time, I will continue with examples of element unpacking through assignment.
Categories: Python | Comments (0) | PermalinkDebugging Matplotlib (Part 8)
Posted by Mark on May 26, 2022 at 06:44 | Last modified: March 26, 2022 11:24Getting back to the objectives laid out here, I completed #1 in Part 4, #2-3 in Part 5, and #5 in Part 6. I will resume with objective #4: randomly select five Fridays as trade entries.
This line is pretty straightforward:

Finally, this snippet allows me to conquer objective #6:
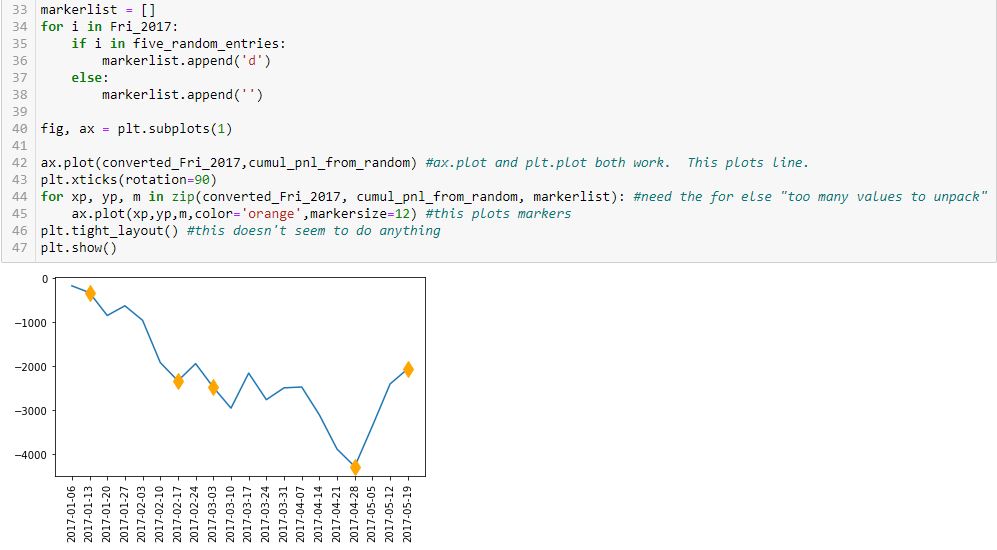
This is actually somewhat complex code for a beginner like me. I will go over a few points.
First, note that I have simplified the graph from two subplots to just one. The reason for including two subplots earlier was only to compare tick labels on the x-axis.
Second, look at the syntax of L45. The arguments are x-values, y-values, marker code, color, and markersize. L42 is an abbreviated version with just the first two arguments. L45 plots the markers while L42 plots the line. How does this work?
In L42, the arguments are datatype list.
In L45, the datatype is more complicated. The first three arguments of L45 are generated in L44 from a zip function. From W3Schools.com:
> The zip() function returns a zip object, which is an iterator of tuples where
> the first item in each passed iterator is paired together, and then the second
> item in each passed iterator are paired together etc.
The zip function itself produces a zip object. Trying to directly unpack the object into variables does not work:
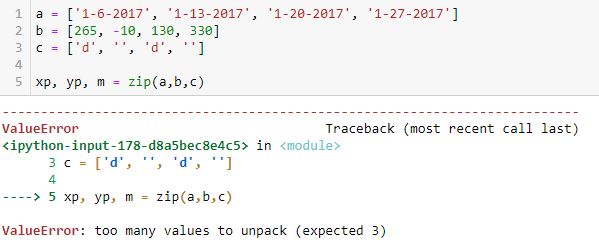
I’m still trying to understand what the “too many values” are. I would expect to get a list of (xp, yp, m) tuples from this.
As it turns out, I can get such a list with the list constructor:

Like the list constructor, the for loop is an iterator that goes over the iterable until nothing is left. Each time, it unpacks three values from the zip object: one from each list. These then get presented to L45 as the x-value, y-value, and marker code. This plots a set of points showing up as diamond markers or blank instead of a continuous line because each time three separate values are presented rather than two lists being presented at once? It’s hard for me to articulate this, which suggests that I don’t fully understand it yet.
Next time, I will do a bit more digging in order to explain this better.
In the meantime, mission accomplished for all six objectives!
Categories: Python | Comments (0) | PermalinkDebugging Matplotlib (Part 7)
Posted by Mark on May 24, 2022 at 07:10 | Last modified: March 24, 2022 11:17I will pick up today by discussing why the x-axis labels are different for the lower subplots presented in Part 6.
To clarify some terminology, I have been saying “x-axis labels,” which I think is adequately descriptive and perhaps even correct. In different online forums, I have seen mentions of “tick labels” and “tick locations.” The 1st and 22nd of each month are tick locations on a date axis. The tick labels are what get printed at those locations. For dates on a date axis, tick locations and tick labels are identical.
The best answer I received to the original question says that matplotlib (MPL) is probably doing with dates what it does with numbers: calculating evenly-sized intervals to fit the plot (based on first and last values). He reports tick locations at the 1st and 15th of each month, though, which makes more sense as “evenly-sized.” The 21 days followed by 7-10 days I get at the 1st and 22nd of each month are lopsided. Although I still lack explanation for the latter, I did find this SO post showing the same thing (no explanation given there, either).
With regard to this line:
> converted_Fri_2017 = [d.strftime(‘%Y-%m-%d’) for d in Fri_2017] #list comprehension
Values lose meaning when converted to strings. MPL spaces strings evenly without regard to any numeric or date value.
String conversion works in this instance because tick locations = tick labels, but other cases could present problems. One such case would be non-fixed-interval trade entry dates. Another example would be a longer time horizon where too many tick labels may render the x-axis illegible. If left as dates (or datetimes: both worked the same for me) then MPL could potentially scale accordingly (see first sentence of paragraph #3, above), but converting to strings robs MPL of this opportunity.
Much functionality remains with regard to ax.xaxis.set_ticks(), ax.set_xlim(), ax.set_xticks(), ax.set_xticklabels(), ax.tick_params(), plt.setp(), AutoDateLocator, ax.xaxis.set_major_locator(MultipleLocator()) from Part 3, etc. The list goes on, and solutions are varied based on version. That is to say they may have worked when posted, but if subsequent versions have been released (especially with previous functionality deprecated), those solutions may no longer be suitable.
I do not plan to write an encyclopedia of all the available functionality. I will resort to picking and choosing based on any particular needs I have at a given time.
Categories: Python | Comments (0) | PermalinkDebugging Matplotlib (Part 6)
Posted by Mark on May 19, 2022 at 06:28 | Last modified: March 23, 2022 11:06I left off with a seemingly counterintuitive situation where plt.xticks() either effects something yet to be generated or gets undone by something later in the program. After completing that last post, though, I had a shocking realization: I THINK I KNOW THE ANSWER AS A RESULT OF MATPLOTLIB EXCEPTIONS HAVING BEEN RAISED IN MY PAST WORK!
Exceptions are usually frustrating because they force me to problem solve something I inadvertently did wrong. Now, that past frustration proves quite beneficial in leaving the indelible image in my mind of a completely blank graph.
Let me simply the code to include only the imported modules and the first graphing line:
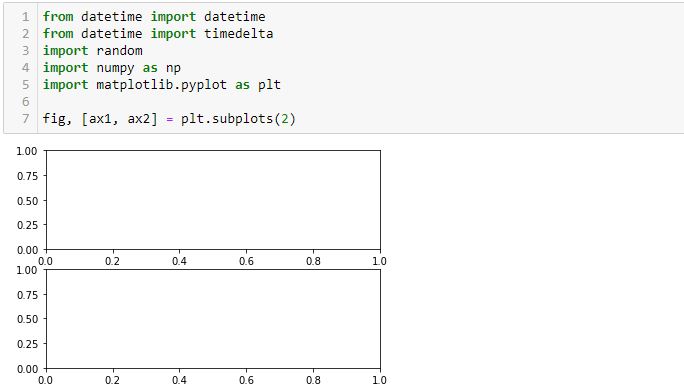
I completely erred in my reasoning throughout the last four paragraphs of Part 5. Neither L3 nor L6 draws any axes. All axes are generated in L1 and this includes the “last [second set of] axes.” L4 and L7 both operate on the second set of axes defined in L1, which is why only the x-axis labels of the lower graph were rotated.
This makes more sense. There is no retroactive operation and no need to hold a command in memory for something not yet generated—both of which seem very “unpythonic.”
Having said all that, experiencing a natural high, and catching my breath, this snippet produces the desired outcome:
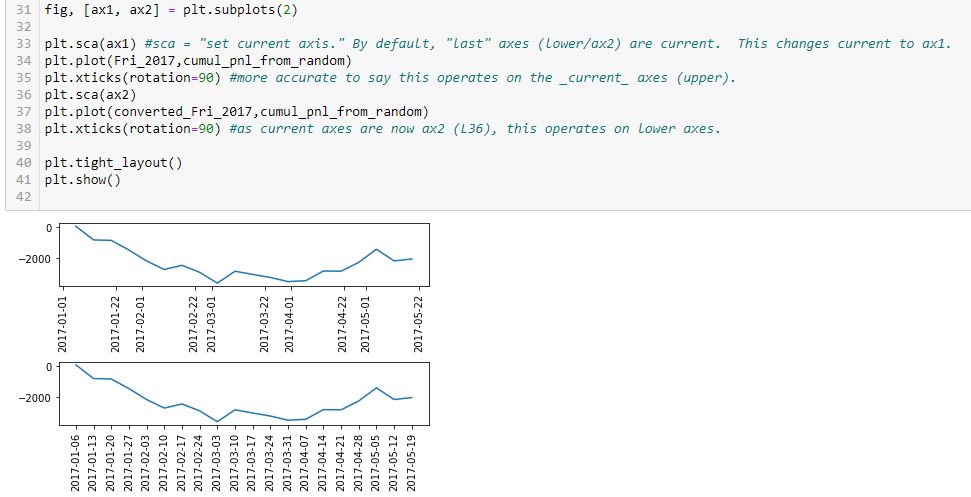
Technically correct is to say current axes are those drawn last by default. Current axes may be explicitly set as shown here. This is how to vary the target of plt.xticks() to get x-axis labels rotated on both graphs.
Now…
Why is the spacing of x-axis labels different on these two graphs?
I will address that next time.
Categories: Python | Comments (0) | PermalinkDebugging Matplotlib (Part 5)
Posted by Mark on May 16, 2022 at 07:27 | Last modified: March 22, 2022 16:42Last time, I laid out some objectives to more simply re-create the first graph shown here. I will continue that today.
Objectives #2-3 are pretty straightforward:

In L2, the arguments for random.randint() are inclusive. You can see a -1000 as part of the first list at the bottom.
Also, note the second line of output is also a list. np.cumsum() generates an array, but the list constructor (in L4) converts this accordingly. Using np.cumsum() does this in one line as opposed to a multi-line loop, which could be used to iterate over each element of the first list subsequently adding to the last item of an incrementally-growing cumulative sum list.
Not seen are a couple additional modules I need in order to use these two methods:
> import random
> import numpy as np
I am going to skip ahead to objective #5 for the time being: the graph. Here is my first [flawed] attempt:
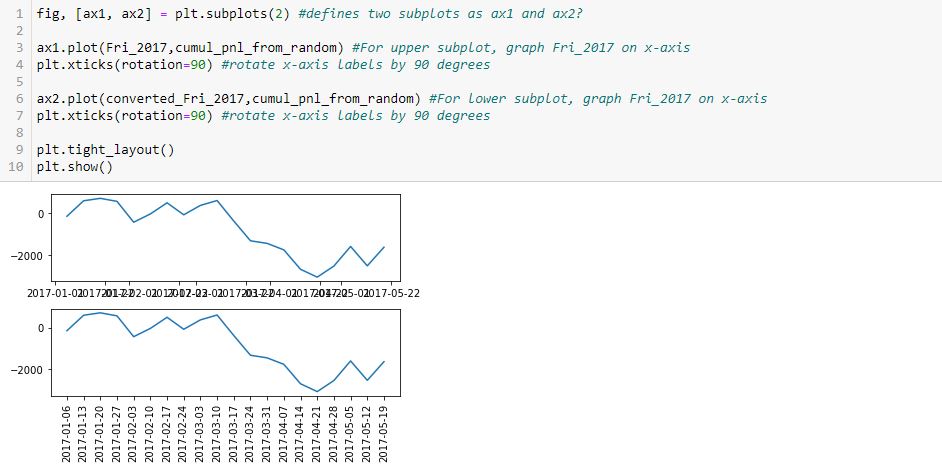
As you can see, the x-axis labels are rotated in the lower subplot but not rotated [and thereby rendered illegible] in the upper. Why do L4 and L7 not accomplish this for both subplots, respectively?
After googling this question a few different ways and looking through at least 20 different posts, the best response I found is this one from Stack Overflow: [no matter where the line appears in the code] “plt manipulates the last axis used.” Here, the last subplot is rotated but the first is not. What confuses me here is where plt.xticks() appears. In order to get the output seen, does the first subplot get rotated by L4 only to be unrotated with generation of the subsequent [last] axis at L6? Does L7 then rotate the x-axis labels on the subsequent [last, or lower] subplot?
I find it extremely counterintuitive for a later line in the program to undo an earlier one because the earlier graph has already been drawn. I can test whether L7 actually rotates the x-axis labels in the lower subplot by commenting it out:
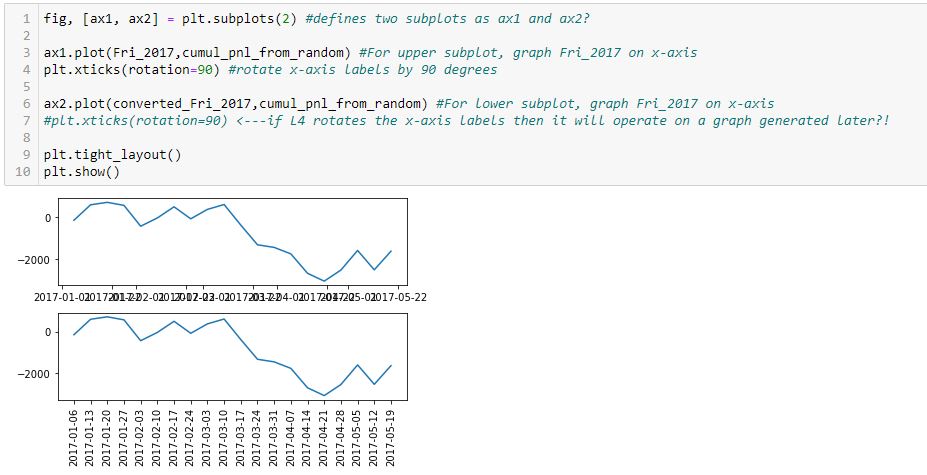
Indeed, this output is the same as the previous, which suggests a later line does not undo an earlier one. Rather, the earlier line effects a graph drawn later.
How does that work, exactly?
Categories: Python | Comments (0) | PermalinkDebugging Matplotlib (Part 4)
Posted by Mark on May 13, 2022 at 07:24 | Last modified: March 22, 2022 10:27Last time, I resolved a couple complications with regard to the x-axis. Today I want to tackle the issue of plotting a marker at select points only as shown in the first graph here.
Here is a complete account of what I have in that graph:
- Cumulative PnL on the y-axis that is available every week
- Datetime x-axis
- Markers on the line plot on where new trades begin
I cobbled together some solutions from the internet in order to make this work. I finally realized it’s not about plotting the line and then figuring out how to erase certain markers or plotting just the markers and figuring out how to connect them with a line. Rather, I must plot the line without markers first, and then plot all points (with marker or null) on the same set of axes:
> axs[0].plot(btstats[‘Date’],btstats[‘Cum.PnL’],marker=’ ‘,color=’black’,linestyle=’solid’) #plots line only
> for xp, yp, m in zip(btstats[‘Date’].tolist(), btstats[‘Cum.PnL’].tolist(), marker_list):
> axs[0].plot(xp,yp,m,color=’orange’,markersize=12) #plots markers only (or lack thereof)
This took days for me to figure out and required a paradigm shift in the process.
Does it really needs to be that complicated? I am going to re-create the graph with a simpler example in order to find out.
Here’s a rough list of objectives for coming up with data to plot:
- Generate a list 2017_Fri 20 consecutive Fridays starting Jan 1, 2017.
- Generate random_pnl_list of 20 simulated trade results from -1000 to +1000.
- Generate cumul_pnl_from_random, which will be a list of cumulative PnL based on random_list.
- Randomly determine trade_entries: five Fridays from _2017_Fri.
- Plot cumul_pnl line.
- Plot markers at trade_entries.
This accomplishes objective #1:
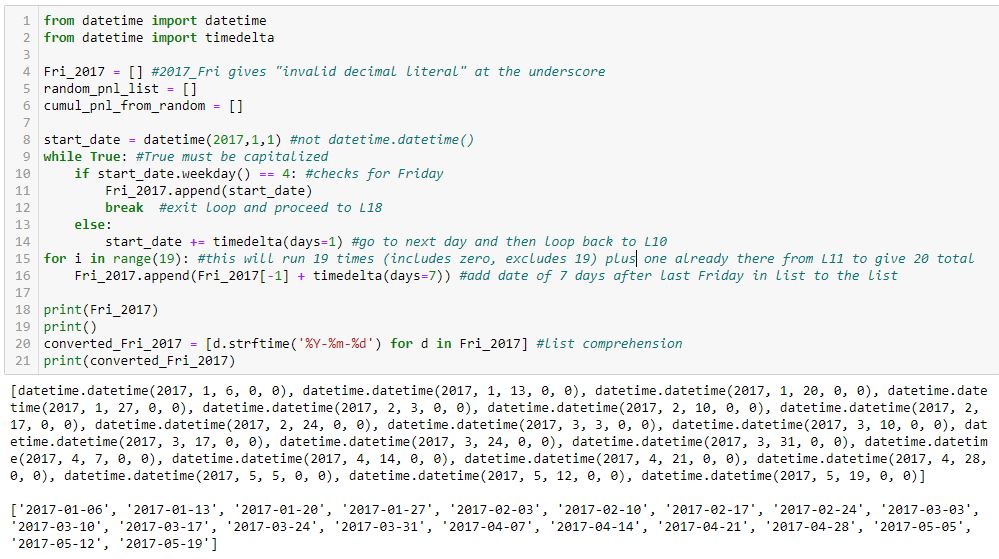
I tried to comment extensively in order to explain how this works.
Two lists of dates are shown in the output at the bottom. The first list is type datetime.datetime, which is a mess. The second list is cleaned up (type string) with L20.
I will continue next time.
Categories: Python | Comments (0) | PermalinkDebugging Matplotlib (Part 3)
Posted by Mark on May 10, 2022 at 07:07 | Last modified: March 16, 2022 14:44Today I resume trying to fix the x-values and x-axis labels from the bottom graph shown here.
As suggested, I need to create a list of x-values. Even better than a loop with .append() is this direct route:
> randomlist_x = list(range(1, len(randomlist + 1))
This creates a range object beginning with 1 and ending with the length of randomlist + 1 to correct for zero-indexing. The list constructor converts that to a list. Now, I can redo the graph:
> fig, ax = plt.subplots(1)
>
> ax.plot(randomlist_x, randomlist, marker=’.’, color=’b’) #plot, not plt
> plt.show()
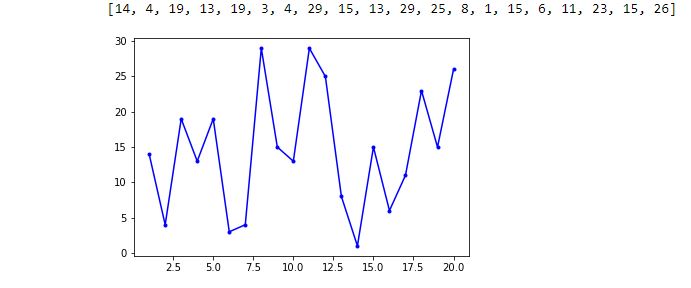
The one thing I can see is decimals in the x-axis labels, which is not acceptable. Beyond that, I don’t have much clarity on the graph so I will add the following to show grid lines:
> plt.grid()
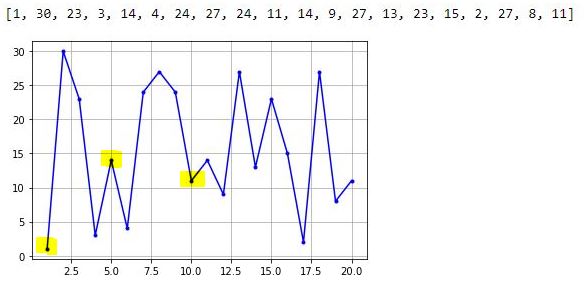
I can now clearly see the middle highlighted dot has an x-value of 5. Counting up to x = 10 for the right highlighted dot, I have confirmation that each dot has an x-increment of 1. The highlighted dot on the left is therefore at x = 1. I have therefore accomplished my first goal from the third-to-last paragraph of Part 2.
To get rid of the decimal x-axis labels, I need to set the major tick increment. This may be done by importing this object and module and following later with the lines:
> from matplotlib.ticker import MultipleLocator
> .
> .
> .
> ax.xaxis.set_major_locator(MultipleLocator(5))
> ax.xaxis.set_minor_locator(MultipleLocator(1))
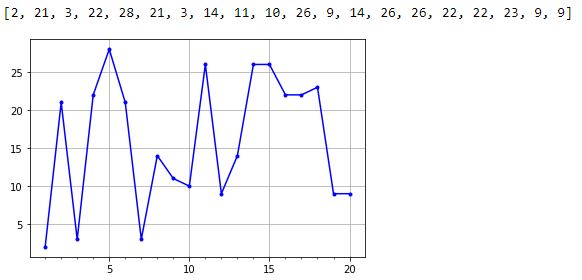
The major and minor tick increments are now 5 and 1, respectively, and the decimal values are gone.
Thus far, the existing code is:
> from matplotlib.ticker import MultipleLocator
> import matplotlib.pyplot as plt
> import numpy as np
> import pandas as pd
> import random
>
> randomlist = []
> for i in range(20):
> n = random.randint(1,30)
> randomlist.append(n)
> print(randomlist)
>
> randomlist_x = list(range(1, len(randomlist)+1))
> fig, ax = plt.subplots(1)
>
> ax.plot(randomlist_x, randomlist, marker=’.’, color=’b’) #plot, not plt
> ax.xaxis.set_major_locator(MultipleLocator(5))
> ax.xaxis.set_minor_locator(MultipleLocator(1))
>
> plt.grid()
> plt.show()
I will continue next time.
Categories: Python | Comments (0) | PermalinkDebugging Matplotlib (Part 2)
Posted by Mark on May 5, 2022 at 07:20 | Last modified: March 15, 2022 11:40In finding matplotlib so difficult to navigate, I have been trying different potential solutions found online. Some have an [undesired] effect and others do nothing at all. Instances of the latter are particularly frustrating and leave me determined to better understand. Today I will begin explaining what I aim to do with visualizations in the backtesting code.
The first graph I wish to present is cumulative backtested PnL on a daily basis. I create a dataframe column ‘Cum.PnL’ to calculate difference between current and original position price. To each entry in this column, I add realized_pnl. Whenever a trade is closed at profit target or max loss, I increment realized_pnl by that amount.
Graphing this results in a smooth, continuous cumulative PnL curve except for one extreme gap. Closer inspection reveals the price of one option on this particular day over $50 more than it should be, which translates to the $5,000+ loss seen here:
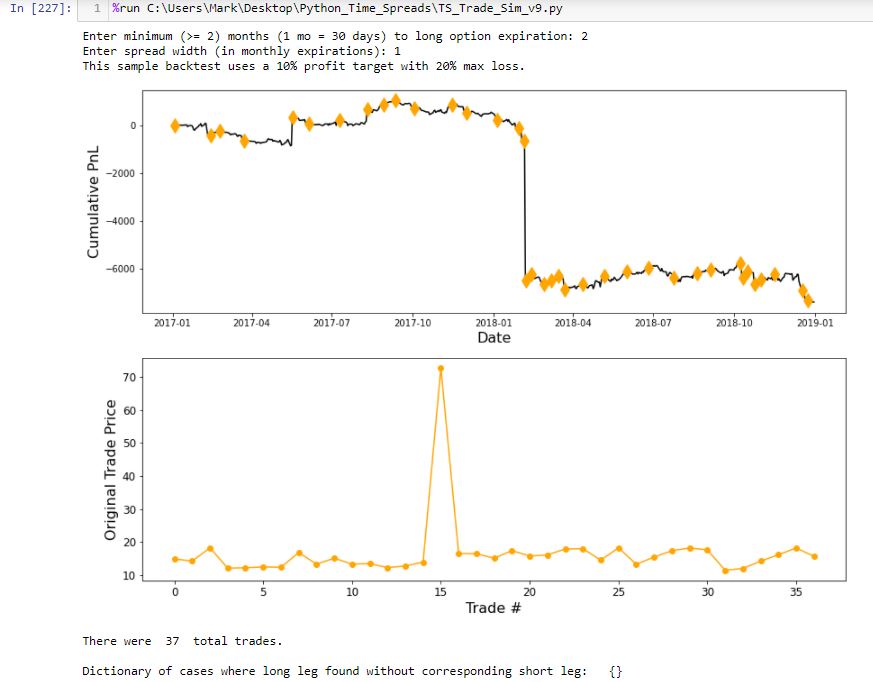
The lower graph shows initial position price and makes it clear that something is way out-of-whack with trade #15. I manually edit that entry in the data file.
The upper graph includes an orange diamond whenever a new trade begins. I endured days of frustration trying to figure out how to do this. To better understand my solution, I will create a simpler example devoid of the numerous variables contained in my backtesting code and advance one step at a time to avoid quirky errors.
First, I will import packages (or modules):
> import matplotlib.pyplot as plt
> import numpy as np
> import pandas as pd
> import random
Next, I will create a random list:
> randomlist = []
> for i in range(20):
> n = random.randint(1,30)
> randomlist.append(n)
> print(randomlist)
This prints out a 20-element list of random integers between 1 and 30. A few iterations got me this:
[30, 24, 3, 29, 20, 7, 29, 25, 25, 20, 15, 24, 8, 13, 9, 14, 19, 30, 1, 5]
I like this example because it has both 1 and 30 in it to demonstrate inclusivity at each boundary.
Next, I will invoke matplotlib’s “simplicity” by generating a graph in just three (not including the blank) lines:
> fig, ax = plt.subplots(1)
>
> ax.plot(randomlist, marker=’.’, color=’b’) #plot, not plt
> plt.show()
So far, so good!
I now want to fix two issues with the x-axis. Because I did not specify x-values, these are plotted by default as zero-indexed order in the data point sequence. This assigns x-value 0 to the first data point, 1 to the second, etc. I want 1 for trade #1, 2 for trade #2, etc. The other issue is that because all x-values are integers, I do not want any decimals in the x-axis labeling.
My solution will be to create a list of numbers I want plotted on the x-axis. The downside to this, however, is loss of matplotlib’s automatic scaling, which it sometimes does very well as seen on the ‘Date’ axis above. Maybe this will still work with integers. We shall see.
I will continue next time.
Categories: Python | Comments (0) | PermalinkDebugging Matplotlib (Part 1)
Posted by Mark on May 3, 2022 at 07:28 | Last modified: March 11, 2022 16:28Matplotlib is giving me fits. In this blog mini-series, I will go into the What and try to figure out the Why.
The matplotlib website says:
> Matplotlib is a comprehensive library for creating static, animated, and interactive
> visualizations in Python. Matplotlib makes easy things easy and hard things possible.
The DataCamp (DC) website says:
> Luckily, this library is very flexible and has a lot of handy, built-in defaults that
> will help you out tremendously. As such, you don’t need much to get started: you
> need to make the necessary imports, prepare some data, and you can start plotting
> with the help of the plot() function! When you’re ready, don’t forget to show your
> plot using the show() function.
>
> Look at this example to see how easy it really is…
I have found matplotlib to be the antithesis of “easy.” I am more in agreement with this previous DC paragraph:
> At first sight, it will seem that there are quite some [sic] components to consider
> when you start plotting with this Python data visualization library. You’ll probably
> agree with me that it’s confusing and sometimes even discouraging seeing the
> amount of code that is necessary for some plots, not knowing where to start
> yourself and which components you should use.
Using matplotlib is confusing and certainly discouraging. Many things may be done in multiple ways, and compatibility is not made clear. Partially as a result, I think some things do absolutely nothing. Support posts are available on websites like Stack Overflow, Stack Abuse, Programiz, GeeksforGeeks, w3resource, Python.org, Kite, etc. Questions, answers, and tutorial information spans over a decade. Some now “deprecated” solutions no longer work. Also adding to the confusion are some solutions that may only work in select environments, which is not even something I see discussed.
What I do see discussed is how easy and elegant matplotlib is to use. I seem to be experiencing a major disconnect.
Maybe the difference is the simplicity of the isolated article examples in contrast to the complex application I am trying to implement. Why would my application be more complex than anyone else’s, though? I am trying to develop a research tool where the results are unknown. While different from writing sample code to present already-collected data, that would be a weak excuse. Discovering previously-hidden relationships is a common motivation behind data visualization.
To learn programming with matplotlib, my rough road has left me only one path: debug the process to understand why my previous attempts have failed. That is where I will start next time.
Categories: Python | Comments (0) | Permalink