Data Type Conversions with the Automated Backtester
Posted by Mark on October 18, 2022 at 06:45 | Last modified: June 22, 2022 08:36I’ve struggled mightily trying to figure out how to handle types for the option data. I think the current solution may be as good as any and today I’m going to discuss how I got to this point.
The data file is .csv with the following [skipping position zero] fields:
- Date (e.g. 17169)
- DTE (e.g. 1081)
- Stock Price (e.g. 2257.83)
- Option Symbol (e.g. SPX 191220P02025000)
- Expiration (e.g. 18250)
- Strike (e.g. 2025)
- Mean Price (e.g. 203.2)
- IV (e.g. 0.209406)
- Delta (e.g. -0.30844)
- Vega (e.g. 13.1856)
- Gamma (e.g. 0.000417)
- Theta (e.g. -0.12758)
For now, I need the following fields as integers (floats for the decimal portion): 1, 2, 5, 6 (3, 7, 8, 9, 12).
Iterating over the first line of data in the file (skipping the header) with L59 (seen here) yields:

Every field I need as an integer comes up with a .0 at the end. When I try to convert to integer with int(), I get a traceback:
> ValueError: invalid literal for int() with base 10: ‘17169.0’.
I can use int(float())) every time I need to encode data from these columns. I do this 21 times in the program. It may seem like an a lot of unnecessary conversion, but I don’t want to see those trailing zeros in the results file.
If I understood why this happens in the first place, then I might be able to nip it in the bud.
Here’s a short code that works:
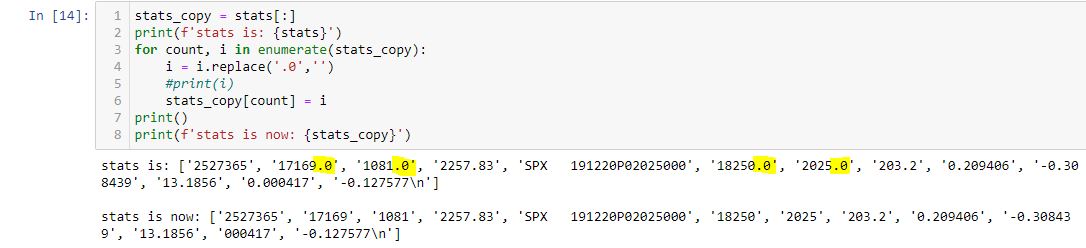
Note that each trailing zero (highlighted) is eliminated. This seems like a lot of preprocessing. The fields remain as strings (note the single quotes) and I still have to convert them to integers.
Is all this faster than 21 instances of int(float())?
I mentioned timers a couple times in this post discussing backtester logic. The following is one approach:
import time
start_time = time.time()
elapsed_time_log = open(r”C:\path\timelog.csv”,”a”)
——————-BODY OF PROGRAM——————-
now = datetime.now()
dt_string = now.strftime(“%m/%d/%Y %H:%M:%S”)
end_time = time.time()
elapsed_time = end_time – start_time
comment = ‘v.9′
print(dt_string,’ ‘, elapsed_time,’ ‘, comment, file=elapsed_time_log)
elapsed_time_log.close()
This code snippet appends a line to a .csv file with time and date, elapsed time, and a comment describing any particular details I specify about the current version. This will give me an idea how different tweaks affect program duration.
As a final note, the code screenshot shown above does not work if L1 reads stats_copy = stats because the original list then changes. This gave me fits, and is probably something every Python beginner encounters at least once.
What’s the problem?
With stats_copy = stats, I don’t actually get two lists. The assignment copies the reference to the list rather than the actual list itself. As a result, both stats_copy and stats refer to the same list after the assignment. Changing the copy therefore changes the original as well.
Aside from the slicing implemented in L1, these methods should also work:
- stats_copy = stats.copy()
- stats_copy = list(stats)