Backtester Logic (Part 3)
Posted by Mark on August 15, 2022 at 06:49 | Last modified: June 22, 2022 08:34I included a code snippet in Part 2 to explain how the wait_until_next_day flag is used in the early stages of the backtesting program. I mentioned that once the short option is addressed (either via finding long/short branches or updating long/short branches), the program should skip ahead in the data file to the next historical date.* This begs the question as to where in the program current_date gets assigned. Today I will take a closer look to better understand this.
The find_long branch (see control_flag here) assigns a value to trade_date. Do I need this in addition to current_date? I created trade_date to mark trade entry dates and on trade entry dates, the two are indeed identical. I could possibly use just current_date, eliminate trade_date, and add some lines to do right here with the former what I ultimately do with the latter. This is worthy of consideration and would eliminate what may be problematic below.
The find_short branch has two conditional blocks—the first of which checks to see if historical date differs from trade_date. This could only occur if one leg of the spread is found, which implies a flaw in the data file. In this case, trade_date is added to missing_s_s_p_dict, control_flag (branch) is changed to find_long, and a continue statement returns the program to the top of the loop where next iteration (row of data file) begins. The process of finding a new trade commences immediately because wait_until_next_day remains False.
The other conditional block in the find_short branch includes a check to make sure historical date equals trade_date. This seems redundant since the first conditional block establishes them to be different. I could probably do one if-elif block instead of two if blocks since the logic surrounding date is mutually exclusive. This may or may not be more efficient, but this second conditional block also has some additional logic designed to locate the short option—additional logic that, as above, could pose a problem if the data file is flawed.
At the end of this second conditional block, wait_until_next_day is set to True but current_date is not assigned. This seems problematic because L66 (see Part 2) will be bypassed, wait_until_next_day will be reset to False, and the flag will basically fail as rows with the same historical date will be subsequently evaluated rather than skipped. Remember, for the sake of efficiency, every trading day should include either finding or updating: not both. How much does this matter?
I will continue next time.
*—Historical date is a column of the data file corresponding to a particular trading day.
Time Spread Backtesting 2022 Q1 (Part 7)
Posted by Mark on August 12, 2022 at 07:14 | Last modified: May 2, 2022 13:49I left off backtesting trade #12 from 3/14/22 with the base strategy shown here.
After the second adjustment, SPX peaks 11 days later at 4626 with position looking like this:
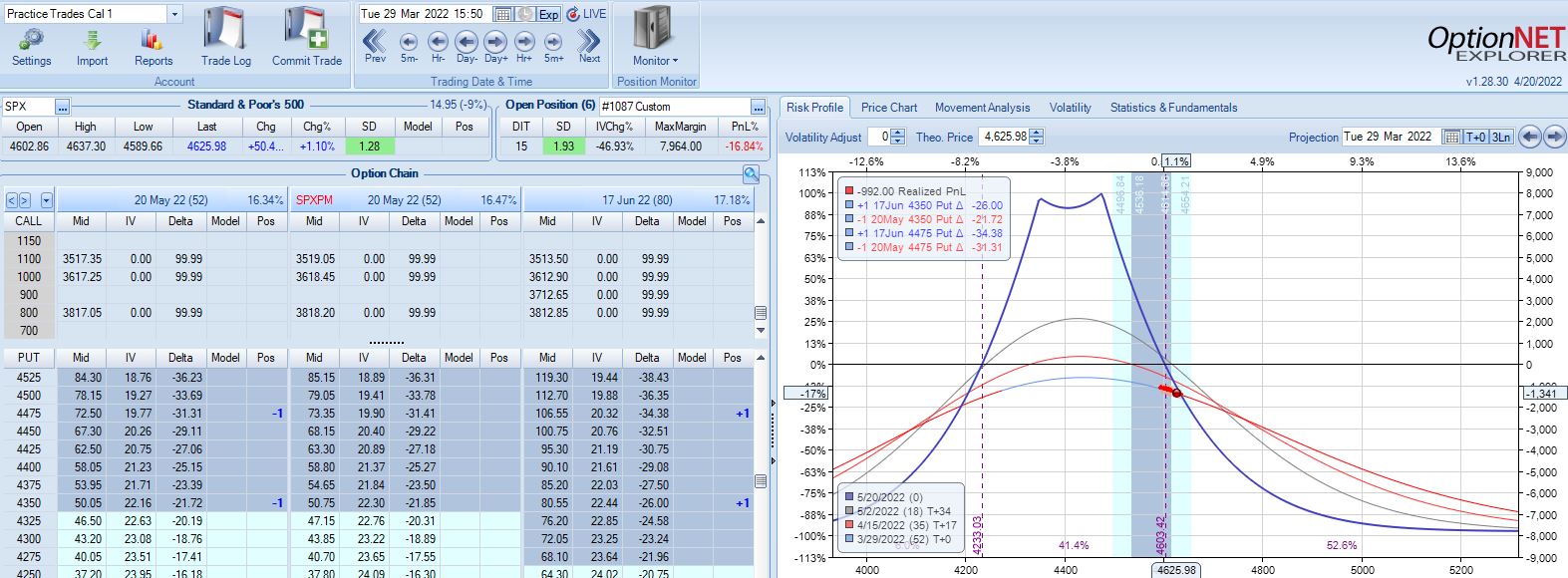
SPX is up 1.93 SD in 15 days and the trade is down 16.9%. The risk graph looks scary, but TD is still 4. Furthermore, having already adjusted twice I have nothing left to do according to the base strategy except wait another day.
On 28 DIT, SPX is in the middle of the expiration tent with trade up 1%.
On 38 DIT, SPX is again near the middle of the expiration tent with trade up 8%.
Three trading days plus a weekend later (24 DTE), the market has collapsed with Avg IV soaring from 19.3% to 28.9%:
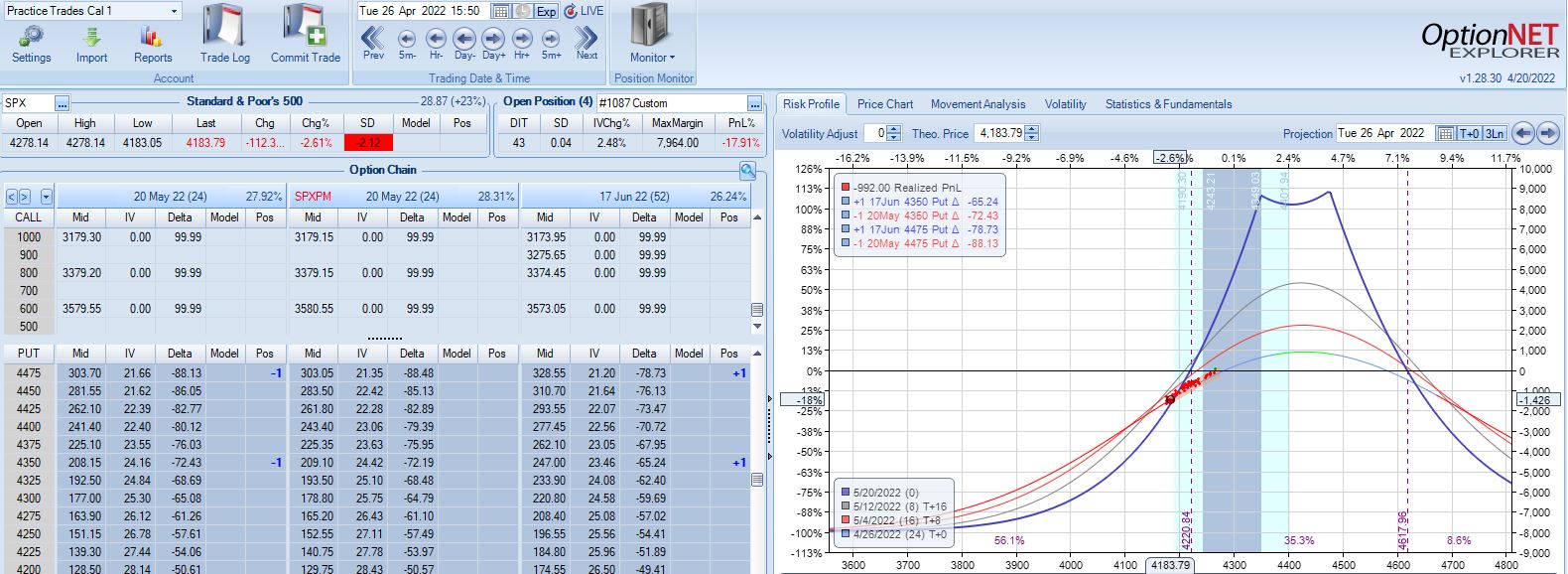
This is an adjustment point since the trade had recovered to profitability since the last adjustment.
In live trading, I’d have a tough time adjusting here knowing my exit is three days away. This is a good example of the second deadline discussed in Part 6. I could exit without adjusting and take the big loss, which would still be better than the market going against me [big] again sticking me with an even larger loss.
Anytime I’m staring a big loss in the face, I need to realize it’s just one trade. This is also a big whipsaw (adjusted twice on the way up and then a third time on the way back down). Such whipsaws do not seem to happen often.* Accepting a big loss may be easier when realizing how unusual the situation is to cause it.
Two trading days later at 22 DTE, I find myself in another challenging spot:
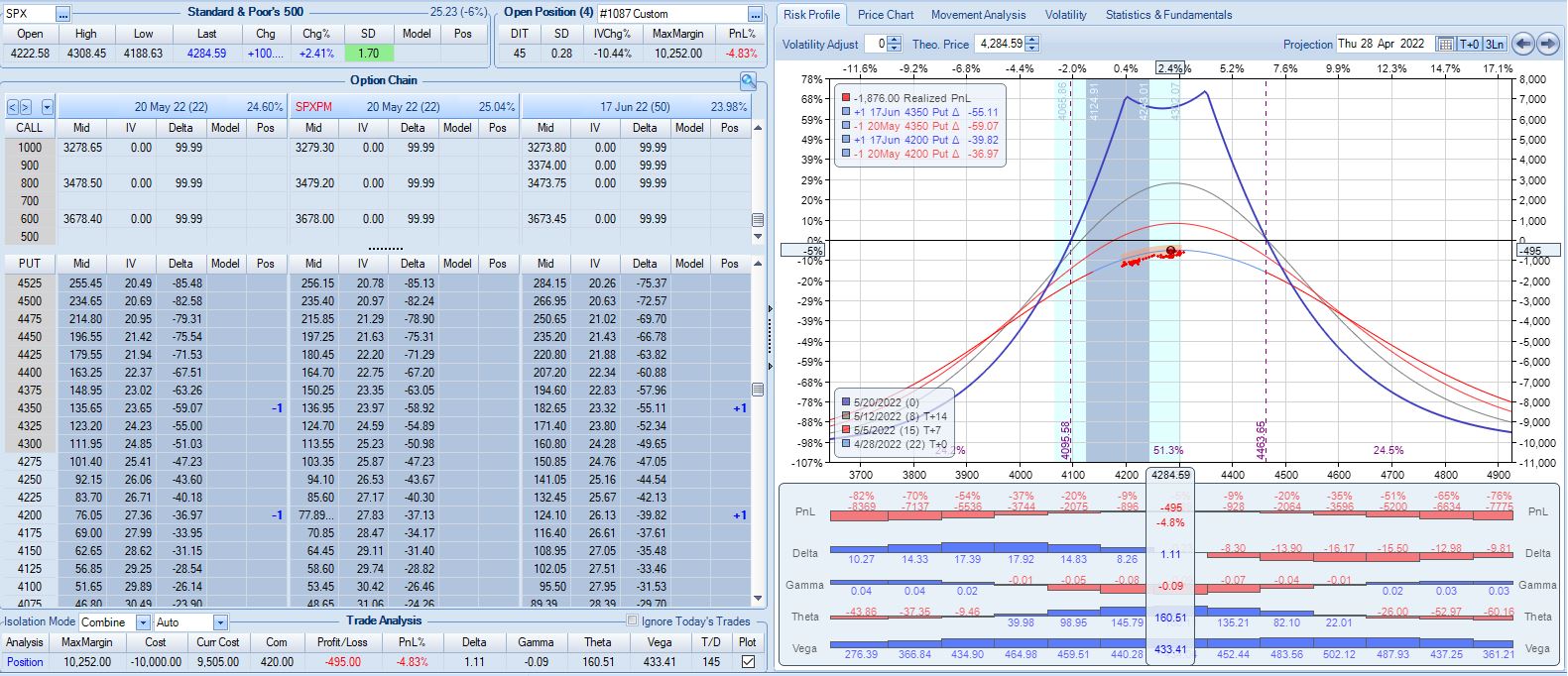
Nothing in the base strategy tells me to exit now, but should I consider it given the way this trade has progressed? It’s hard to say without any data. I am fortunate to be down only 5% with one day remaining after being down 15% twice.** If trading systematically based on a large sample size then I should stick with the guidelines. In all my Q1 2022 backtesting, this is the only trade that has been adjusted three times so finding a large sample size of similar cases may prove difficult.
This particular trade has given me lots to consider! I will finish discussing it next time.
*—If I wanted to add a whipsaw-preventing guideline (or test to see how often this occurs), I could plan
to exit at the center or opposite end of the expiration tent after an adjustment is made.
**—The relevant exit criterion to be tested would be something like “if down more than X% at any point,
lower profit target from 10% to Y%.” Another could be “if under 28 DTE, lower profit target to Z%.”
Backtester Logic (Part 2)
Posted by Mark on August 9, 2022 at 07:11 | Last modified: June 22, 2022 08:34Last time, I discussed a plan to iterate through data files in [what I think is] an efficient manner by encoding elements only when proper criteria are met. Today I will continue discussing general mechanics of the backtesting program.
While the logic for trade selection depends on strategy details, the overall approach is dictated by the data files. The program should ideally go through the data files just once. Since the files are primarily sorted by historical date and secondarily by DTE, in going from top to bottom the backtester needs to progress through trades from beginning to end and through positions from highest to lowest DTE. This means addressing the long leg of a time spread first as it has a higher DTE.
Finding the long and short options are separate tasks from updating long and short options once selected. When finding, the backtester needs to follow trade entry guidelines. When updating, the backtester needs to locate previously-selected options and evaluate exit criteria to determine whether the trade will continue. I therefore have four branches of program flow: find_long, find_short, update_long, and update_short.
Going back to my post on modular programming, I could conceivably create functions out of the four branches of program flow. Two out of these four code snippets are executed on each historical date because opening and updating a trade are mutually exclusive. I do not see a reason to make functions for this since the program lacks repetitive code.*
Whether finding or updating, once the short option has been addressed the backtester can move forward with calculating position parameters and printing to the results file. For example, in order to calculate P_price = L_price – S_price (see key here), the program needs to complete the find_long / find_short or update_long / update_short branches since the position is a sum of two parts. One row will then be printed to the results file showing trade_status (reviewed in previous link), parameters, and trade statistics.
Since every trading day involves either finding or updating, once the short option has been addressed any remaining rows in the data file with the same historical date may be skipped. For that purpose, I added the wait_until_next_day flag. This is initially set to False and gets toggled to True as needed. Near the beginning of the program, I have:
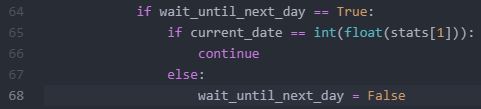
If the flag is True, then the continue statement will return the program to the top where the next iteration (row of the .csv file) begins. This will repeat until the date has advanced at which point the flag will be reset to False.
To complete our understanding of this matter, I need to analyze where current_date is assigned.
I will continue with that next time.
*—Resetting variables is the one exception I still need to discuss.
Time Spread Backtesting 2022 Q1 (Part 6)
Posted by Mark on August 4, 2022 at 06:39 | Last modified: May 2, 2022 10:31Before continuing the manual backtesting of 2022 Q1 time spreads by entering a new trade every Monday (or Tuesday), I want to discuss alternatives to avoid scary-looking graphs (see last post) and cumbersome deadlines.
Scary-looking risk graphs can be mitigated by early adjustment. TD = 3 in the lower graph of Part 5. Perhaps I plan to adjust when TD falls to 3 or less. I used this sort of methodology when backtesting time spreads through the COVID-19 crash. Another alternative, as mentioned in Part 3, is to adjust when above (below) the upper (lower) strike price. To keep adjustment frequency reasonable in this case, I should maintain a minimum distance between the two spreads.
In staying with the ROI%-based adjustment approach, something I can do to limit adjustment frequency is to adjust once rather than twice between trade inception and max loss. The base strategy looks to adjust at -7% and again at -14%. I could adjust only once at -10% and subsequently exit at max loss, profit target, or time stop.
I’ve noticed two types of time spread deadlines that can make for uncomfortable judgment calls. The first is proximity to max loss. When at an adjustment point, if a small market move can still force max loss then I question doing the adjustment at all. For example, why adjust down 17% if max loss lurks -3% away? Even -14% can be questionable because if down just under that one day, I can be down -17% the next, which puts me in the same contentious predicament.
A second awkward deadline I may face is the time stop. Base strategy calls for an exit no later than 21 DTE. Adjustments require time to recoup the transaction fees. At what point does adjustment no longer make sense because soon after the trade will be ending anyway? Rather than adjust at, say, 23 DTE, I could close a bit early in favor of a farther-out spread. Such a condition was not included in the base strategy guidelines but may be worth studying.*
Let’s continue with the backtesting.
Moving forward through 2022 Q3 with SPX at 4168, trade #12 begins on 3/14/22 at the 4175 strike for $7,078: TD 46, IV 28.2%, horizontal skew 0.3%, NPV 270, and theta 50.
First adjustment point is hit two days later with trade down 7%:
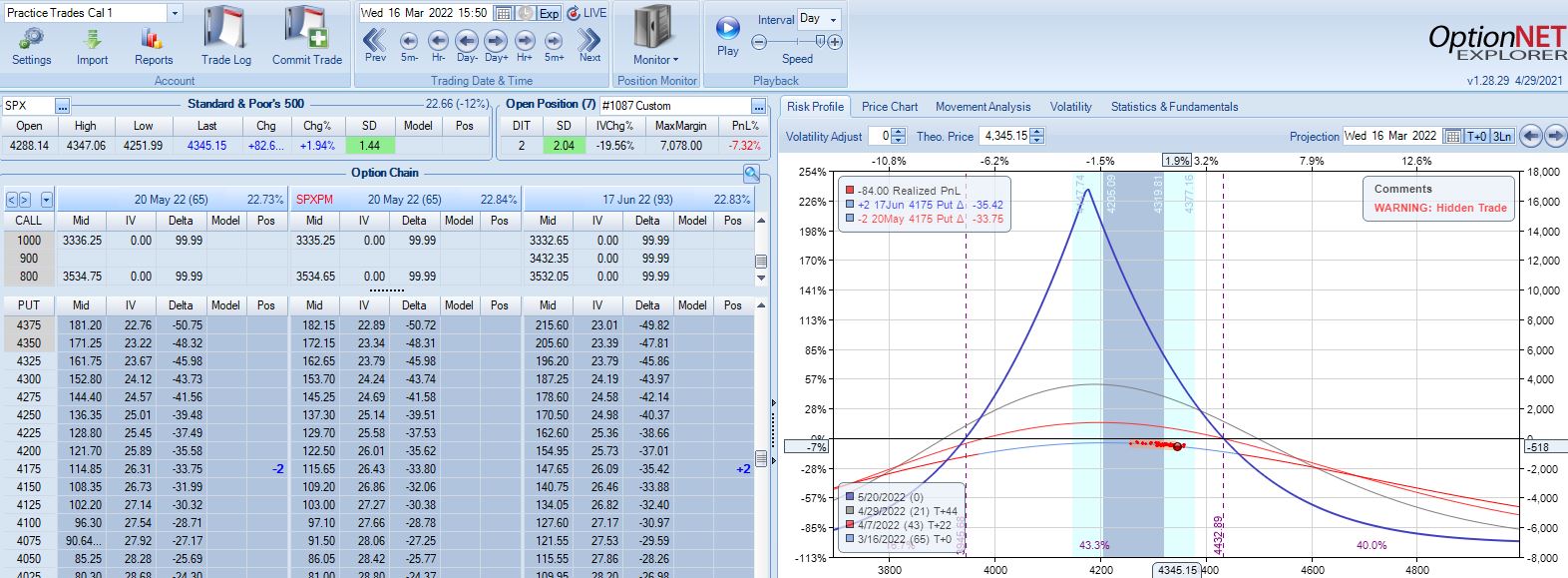
Second adjustment point is hit two days after that. SPX is up 2.38 SD in four days with trade down 16%:
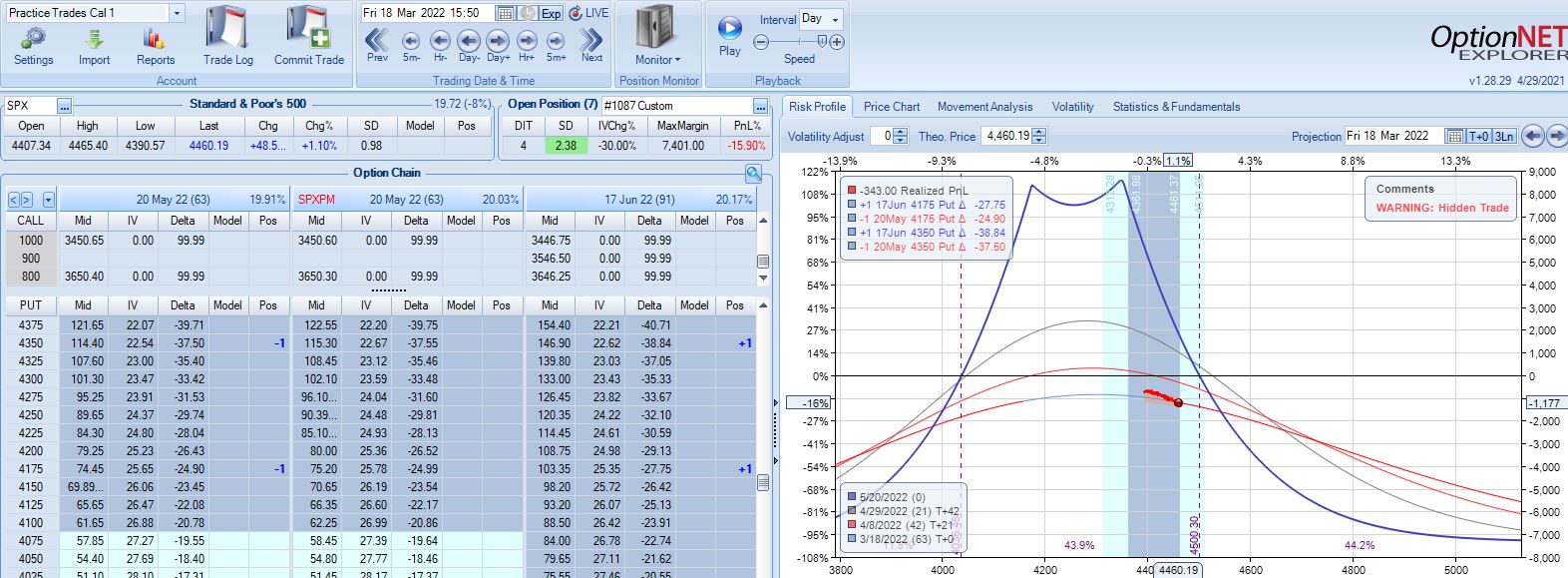
I will continue next time.
*—Aside from varying the drop-dead adjustment DTE, I am also interested to see what happens if
the position is always rolled out at adjustment points whenever the front month is under 60 DTE.
Backtester Logic (Part 1)
Posted by Mark on August 1, 2022 at 07:26 | Last modified: June 22, 2022 08:34Now that I have gone over the modules and variables used by the backtester, I will discuss processing of data files.
My partner (second paragraph here) has done some preprocessing by removing rows pertaining to calls, weekly options, deepest ITM and deepest OTM puts, and by removing other unused columns. Each row is a quote for one option with greeks and IV. I tend to forget that I am not looking at complete data files.
As the backtester scans down rows, option quotes are processed from chronologically ordered dates. Each date is organized from highest to lowest DTE, and each DTE is organized from lowest to highest strike price.
My partner had given some thought to building a database but decided to stick with the .csv files. Although I did take some DataCamp mini-courses on databases and SQL, I feel this is mostly over my head. I trust his judgment.
I believe the program will be most efficient (fastest) if it collects all necessary data from each row in a single pass. I can imagine other approaches that would require multiple runs through the data files (or portions therein). As backtester development progresses (e.g. overlapping positions), I will probably have to give this further thought.
The first row and column of the .csv file are not used. The backtester iterates down the rows and encodes data from respective columns when necessary. The first column is never called. Dealing with the first row—a string header with no numbers—requires an explicit bypass. It could raise an exception since the program evaluates numbers. The bypass is accomplished by the first_bar flag (initially set to True) and an outer loop condition:
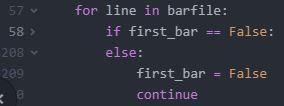
The first iteration will set the flag to False and skip everything between L58 and L208. The bulk of the program will then apply to the second iteration and beyond.
To maximize efficiency, the backtester should encode as little as possible because most rows are extraneous. Backtesting a time spread strategy that is always in the market with nonoverlapping positions requires monitoring 2 options/day * ~252 trading days/year = 504 rows. My 2015 data file has ~120,000 rows, which means just over 0.4% of the rows are needed.
I will therefore avoid encoding option price, IV, and greeks data unless all criteria are met to identify needed rows.
A row is needed if it has a target strike price and expiration month on a particular date but once again, in the interest of efficiency the backtester need not encode three elements for every row. It can first encode and evaluate the date, then encode and evaluate the expiration month, and finally encode and evaluate the strike price. Each piece of information need be encoded only if the previous is a match. Nested loops seem like a natural fit.
I will continue next time.
Categories: Python | Comments (0) | PermalinkCoffee with Professional Commodity Trader (Part 4)
Posted by Mark on July 29, 2022 at 06:55 | Last modified: April 22, 2022 12:09The sunburn has finally healed after nearly two hours outdoors enjoying a Caramel Frappuccino and conversation with our professional commodity trader NK. Today I will wrap up the miscellaneous notes and talk briefly about future directions.
- One of NK’s big concerns is the market activity of March 2020. I refreshed his memory on the COVID-19 market crash (~35%) a couple years ago and asked why he might expect another crash anytime soon. The quick rebound is what scares him. The Fed came to the rescue, which only furthers belief that the stock market cannot go down in a big way. This belief is like playing with fire because nothing is guaranteed and should the Fed not act dovish we could end up with a lasting, catastrophic decline at some future date.
- NK can work remotely but likes the opportunity to go into the office to share ideas and to see other people.
- NK is a proponent of buying OTM VIX futures—maybe even closer to expiration as opposed to farther out—as a hedge for the overall portfolio.
- NK acts in a broker (agent, perhaps?) capacity for clients—some of whom don’t have the faintest idea about how to place a trade. They pay full service $60-$80 commissions, but it may be well worth it for clients who might otherwise make a mistake and lose many times more as a result.
- NK doesn’t trade client accounts in a discretionary manner where they may not know what his strategy is. Rather, clients usually call with something particular they wish to accomplish (e.g. hedging product) or to get advice on devising a strategy that will match their personal market outlook.
Because incorporating and sticking with new trading strategies has proven to be a herculean task for me, in order to make this discussion useful I should aim to start with something small. To this end, tasks I will ultimately need to complete include:
- Learning the symbols for new futures markets.
- Learning the multipliers and “futures math” for new futures [options] markets.
- Gaining a sense of familiarity for the charts.
- Looking at COT reports weekly.
- Learning the margin requirements and commission structure for futures [options] trading.
- Looking around for futures brokerages in case others may offer a better package than what I currently receive.
- Looking around for futures market data providers.
- Backtesting the new futures markets.
While I have brainstormed everything I can think of at the present moment, I repeat that my goal is really to do one [or two] per week [or month]. “Start small” and “look for continuous improvement” are mantras by which I try to live.
And because I will probably need the accountability of this blog to stay on track, I will probably be keeping you posted!
Categories: About Me, Networking | Comments (0) | PermalinkCoffee with Professional Commodity Trader (Part 3)
Posted by Mark on July 26, 2022 at 07:06 | Last modified: April 14, 2022 14:11I recently spent nearly two hours taking in a lot of sun and a conversation with NK, a professional commodity trader. Today I continue presentation of miscellaneous notes from the meeting.
- Because I feel my forte is in strategy development and analysis, I do not want a future job in the financial industry to center around sales. NK agreed, saying that he does not really enjoy talking to customers. He also doesn’t want to be personally responsible for their accounts.
- On a personal note, the latter is one reason why I haven’t been more aggressive in pursuing a money management career. If I have been able to do it for myself, though, then isn’t the logical next step to scale up and do the same for others (see second-to-last paragraph here)? Why not suggest people allocate up to 20% (this second-to-last paragraph) of their portfolios to my trading strategies? Is this mini-series convincing enough?
- NK enjoys working with farmers, who he generally finds humble and informal. He can be dressed down when meeting with them in person as opposed to having to wear a shirt and tie every day.
- Because they believe in their agricultural products, farmers like to be “long everything” (i.e. futures and call options).
- As farmers live and breathe crops and livestock, I live and breathe equities although I hardly want to be “long everything.” Despite over 14 years of full-time trading with decent performance against the benchmarks, I spend more time planning what to do if stocks tank with regard to hedging or even profiting from the downside.
- Unlike the buy-and-hold thesis marketed by retail financial services, I am not convinced that stocks will always rise. Why can’t US stocks do nothing for 30+ years like Japan has experienced with the Nikkei since Dec 1989? NK said that he invests in some Japanese small caps and knows their price history enough to realize Japan’s late-1980s equity market made the US Dotcom bubble look small in comparison (they have now overcorrected to the downside, though).
- For US equities, NK thinks we are due for a major correction or at least a couple years of sideways action because the Fed is currently less accommodative (runaway inflation). If the market were to crash, don’t expect a dovish Fed to save the day [predictions still don’t hold much weight for me no matter who they come from].
I will conclude next time.
Categories: About Me, Networking | Comments (0) | PermalinkCoffee with Professional Commodity Trader (Part 2)
Posted by Mark on July 21, 2022 at 06:40 | Last modified: April 13, 2022 16:16Today I continue with miscellaneous notes from two hours of sun exposure and a delish grande Carmel Frappuccino while conversing with professional commodity trader NK:
- I asked whether he has a desire to work full-time for himself and he said he has recently been doing some contingency planning since he doesn’t expect his current job to last forever. The owner of his firm is getting older and showing signs of questionable judgment and commitment to business decisions that are not in the firm’s best interests.
- NK and some co-workers have formed a trading business to manage assets for friends and family. Capital is invested in land (farms) and tradeable assets.
- NK disagreed with me that we have not had a large sample size of market shocks on which to backtest hedge strategies. Aside from fall 2008, we had the Flash Crash in May 2010, Aug 2011, Aug 2015, Feb 2018, and Mar 2020.
- NK said Brexit in Jun 2016 had a minor effect on the market. The Q4 2018 market selloff was similarly too gradual to really affect term structure and/or cause a major market shock. In contrast, China’s revaluation of the yuan in Aug 2015 had a big impact on stocks and caused IV to spike in a big way.
- With regard to stocks, NK buys stocks that look cheaply valued.
- NK thinks hogs are the best place to start if I want to start trading commodities.
- Look at weekly COT report as a directional guide because investors will not flip from significantly long one week to significantly short the next.
- If for no other reason then as a self-fulfilling prophecy, NK believes commodities are one segment where TA may actually work. He does not believe stock TA has any efficacy.
- NK does not believe short-term strategies are effective for commodities.
- NK does not believe any strategy will work forever. To always be on the lookout for new strategies or tweaks to augment currently profitable ones therefore makes good sense. I agree with this 100%.
- NK and I also agree that hefty doses of ego are on display when it comes to casual discussion about the markets and investing. For this reason, NK does not believe anything he sees on Twitter or other social media.
- NK claims to have made money trading on his own (including full-time for about six months in 2016-7 while between jobs). He doesn’t claim to have killed it, but he believes he has fared well. I would say the same for myself to date (see this blog mini-series).
I will continue next time.
Categories: Networking | Comments (0) | PermalinkCoffee with Professional Commodity Trader (Part 1)
Posted by Mark on July 18, 2022 at 07:15 | Last modified: April 13, 2022 12:38I recently met up with a professional commodities trader (NK) to talk about trading in general. We sat outside Starbucks and I enjoyed a Caramel Frappuccino in the sun for nearly two hours. Once I got through the whipped cream, I found the sun had melted the drink to liquid. 1-2 days later, I also regretted not having sat in the shade.
In any case, here are some miscellaneous notes about our conversation:
- NK believes the permanent portfolio (Harry Browne) is worth looking at with 25% allocated to cash.
- I was talking about potential benefits of time spreads and NK mentioned another (besides horizontal skew and weighted vega) that he couldn’t name or completely describe. This has something to do with IV getting cheaper as options move ITM (maybe involving the second or third derivative of IV).
- NK believes low IV makes options on GC and 6E prohibitive to sell.
- One thought about commodities that makes common sense is to go long (short) when term structure is in backwardation (contango) because price will then move in your favor over time.
- NK is a believer in LT trends for commodities.
- As trend followers, CTAs may have four good years followed by eight bad years, etc. The good years will far exceed the bad, and commodities are generally a good [e.g. inflation] hedge regardless.
- Another idea with commodities, which is probably something most CTAs (as trend followers) employ, is to go long (short) when price is above (below) the 200-SMA. They may get chopped up at times, but they should catch big trends and never incur catastrophic drawdowns.
- NK suggests watching for opportunities to sell options after limit moves when IV explodes because even if market directionally moves against the position, IV contraction may result in profit. He has seen cases where same-strike options in far-apart expirations have been priced equally due to term structure.
- Beware of wide bid/ask spreads on commodity options.
- NK sometimes trades futures options and other times the ETF (options?). He finds the pricing is different and may even be an arbitrage opportunity. As an example, ETF price based on options from the nearest two months of a futures market may not respond as expected if IV explodes in one of those two months (I forgot to ask at this juncture whether 60/40 tax treatment is a factor in making this decision).
- NK previously worked for a brokerage that messed up client PM at initial rollout causing them to blow out accounts.
- NK doesn’t personally trade with PM and didn’t know much about its calculation. He occasionally gets firmwide risk sheets and never realized why it’s broken down into categories between +/- 15% on market price.
I will continue next time.
Categories: Networking | Comments (0) | PermalinkBacktester Variables
Posted by Mark on July 14, 2022 at 06:44 | Last modified: June 22, 2022 08:34Last time I discussed modules including those used by an early version of my backtester. Today I introduce the variables.
For any seasoned Python programmer, this post is probably unnecessary. Not only can you understand the variables just by looking at the program, the names themselves make logical sense. This post is really for me.
Without further ado:
- first_bar is Boolean to direct the outer loop. This could be omitted by manually removing the data file headers.
- spread_count is numeric* to count number of trades.
- profit_tgt and max_loss are numerics. These could be made customizable or set as ranges for optimization.
- missing_s_s_p_dict is a dictionary for cases where long strike is found but short strike is not.
- control_flag is string to direct program flow (‘find_long’, ‘find_short’, ‘update_long’, or ‘update_short’).
- wait_until_next_day is Boolean to direct program flow.
- trade_date and current_date are self-explanatory with format “number of days since Jan 1, 1970.”
- P_price, P_delta, and P_theta are self-explanatory with P meaning “position.”
- H_skew and H_skew_orig are self-explanatory with H meaning “horizontal.”
- L_iv_orig and S_iv_orig are long (L) and short (S) original (at trade inception) option IV.
- ROI_current is current (or trade just closed) trade ROI.
- trade_status is a string: ‘INCEPTION’, ‘IN_TRADE’, ‘WINNER’, or ‘LOSER’.
- L_dte_orig and S_dte_orig are days to expiration for long and short options at trade inception, respectively.
- L_strike and S_strike are strike prices (possibly redundant as these should be equal).
- L_exp and S_exp are expiration dates with format “number of days since Jan 1, 1970.”
- S_exp_mo and L_exp_mo are expiration months in 3-letter format.
- L_price_orig and S_price_orig are option prices at trade inception.
- L_delta_orig and S_delta_orig are delta values at trade inception.
- L_theta and S_theta are current theta values.
- spread_width is number of days between long- and short-option expiration dates.
- P_t_d_orig and P_t_d are original and current TD ratio, respectively.
- PnL is trade pnl.
- test_counter counts number of times program reads current line (debugging).
- trade_list is list of trade entry dates (string format).
- P_price_orig_all is list of trade inception spread prices (for graphing purposes).
- P_theta_orig_price (name needs clarification) is position theta normalized for spread price at trade inception.
- P_theta_orig_price_all is list of position theta values normalized for spread price at trade inception (graphing).
- P_theta_all is list of position theta values at trade inception (graphing).
- feed_dir is path for data files.
- strike_file is the results file.
- column_names is first row of the results file.
- btstats is dataframe containing the results [file data].
- mte is numeric input for minimum number of months until long option expiration.
- width is numeric input for number of expiration months between spread legs.
- file is an iterator for data files.
- barfile is an open data file.
- line is an iterator for barfile.
- add_btstats is a row of results to be added to dataframe.
- realized_pnl is self-explanatory numeric used to calculate cumulative pnl.
- trade_dates_in_datetime is list of string (rather than “days since Jan 1, 1970”) trade entry dates.
- marker_list is list of market symbols ( ‘ ‘ or ‘d’).
- xp, yp, and m are iterators to unpack dataframe elements for plotting.
- ticks_array_raw creates tick array for x-axis.
- ticks_to_use determines tick labels for x-axis.
I will have further variables as I continue with program development and I can always follow-up or update as needed.
*—Exercise: write a code overlay that will print out all variable names and respective data types in a program.