Backtester Logic (Part 9)
Posted by Mark on September 26, 2022 at 06:39 | Last modified: June 22, 2022 08:35Having completed analysis of the first two, I now continue with the update_long and update_short branches.
The conditional skeleton for these two branches of program flow looks like this:*

As discussed in the third paragraph of Part 2, rather than follow trade entry criteria these branches just need to locate previous selections. L134 (for update_long) and L150 (for update_short) look to match strike price and expiration. Short and sweet.
Here are considerations with regard to historical date:
- After find_short, historical date should be advanced to update the spread.
- After update_long, historical date should not be advanced since two legs need to be updated on the same date.
- After update_short, historical date should be advanced assuming the trade remains open.
(1) Near the end of find_short, the wait_until_next_day flag is set to True, but current_date has not yet been assigned. I have already discussed this oversight (near end of Part 3 and beginning of Part 4).
(2) update_long does nothing with the wait_until_next_day flag, and…
(3) In L145, update_short checks to make sure historical date has not advanced before progressing to update. If historical date has advanced, then an exception is raised. This should not happen if the data file is complete unless the short option has expired. Whether it be short option expiration or a predetermined DTE, I still need to build in time-stop logic to handle this.
When any branch of program flow finds a match, encoding from the data file assigns to variables shown in the key.
find_short and update_short include several lines devoted to variable reset. Variable reset prevents previous (stale) values to be used in current calculations. Variable reset will only be done as part of find_short if a short option is not found, which itself in an error. To do this effectively, I will make a list to ensure every variable involved in assignment is subsequently reset.
I will also decide whether a user-defined function to reset variables (as mentioned in Part 2 footnote) is indicated.
Is that the light at the end of the tunnel I might be starting to see?
Here are some other topics I still want to discuss:
- Printing to results file
- trade_status
- Rationale behind btstats
- L121 syntax
- Exit logic
- Encoding process
I will continue next time.
*—As discussed in the Part 6 footnote, I’ve used Atom’s folding feature for display purposes, which
means the higher level (indented) lines are hidden from view.
Backtester Logic (Part 8)
Posted by Mark on September 20, 2022 at 06:57 | Last modified: June 22, 2022 08:35Having tied up several loose ends in the last post, today I want to analyze logic for the find_short branch.
As with find_long (see here), find_short involves a multiple if statement:
![]()
The input variable (see key) from the top of the program is defined as follows:
width = int(input(“Enter spread width (in monthly expirations): “))
L98 searches for a DTE between upper and lower bounds. The difference between bounds is 10 days. The upper bound is the long option expiration minus (28 * width). With 28 or 35 days between expiration cycles, (28 * width) is the highest value it should ever take. The extra 10 [days] should accommodate a 35-day cycle.
If the width covers two (or more) 35-day cycles then this may not work because 7 * 2 = 14 days is more than the 10 provided. Moving the 10 inside parentheses won’t work because width = 4 (the least required to get two 35-day cycles) would allow for a lower bound that is ((4 * 28) + 40) below the upper bound: enough to capture two potential options for the short leg (although the desired longer-dated option will match first if the data file is complete).
To better code L98, I should include the additional days for each three months of width:
DTE > L_dte_orig – ((28 * width) + (10 * ((width + 2) // 3)))
Floor division ( // ) truncates the remainder for positive numbers. For one month, this is 3 // 3 = 1. For three months, this is
5 // 3 = 1. Only when I get to four months, which is 6 // 3 = 2, will 20 additional days be included.
I will make this modification, but for a couple reasons it’s not something I will use anytime soon. First, I really worry about liquidity and option availability for width > 3 because the long will then be very far from expiration and probably lightly traded. Practically speaking, I would only consider a max width of two months. Second, the lower bound seems unnecessary. Any option available in the long expiration should be available in the short as long as the data file is complete.*
If I want to clean the data files, which includes assessing completeness by searching for omitted and erroneous data, then I can create some simple Python scripts. That’s a topic for another post.
L99 looks to match strike price with the long option. One option per expiration cycle should match. I am okay with this line coming after L98 because the more restrictive if statement (see Part 4) may depend on how many expirations are available: a variable number over the years.
L99 also looks to match date with long option purchase. This is redundant because the previous if statement (not shown) checks for this and makes an entry in missing_s_s_p_dict if short not found.
I will continue next time.
*—This brings to mind another problem with 10-point multiples in find_long (see fourth paragraph Part 7).
Far from expiration, I have sometimes noticed that only 25-point strikes are available (and only 50-point
strikes going back many years). Requiring 10-multiple is actually constrained to 50-point strikes in that
case. The difference between one 50-point strike and the next can be much more than 1% of the
underlying in those earlier years, which is enough to make for a clearly directional trade.
Backtester Logic (Part 7)
Posted by Mark on September 12, 2022 at 06:54 | Last modified: June 22, 2022 08:35Today, I want to tie up some loose ends related to multiple topics.
The issue of trading options farther out in time (see paragraphs 3-4 of Part 6) will resurface later when I discuss time spread width. For now it will suffice to say that if I want to increase width, besides trading a longer-dated long option I can also do a shorter-dated short option when slippage (open interest, volume, liquidity, etc.) is a concern.
L71 (see Part 4) filters for a 10-point strike by requiring the remainder of strike price / 10 = 0. Due to liquidity concerns, I would prefer to trade only 25-point strikes. My second choice would be 10-, and 5-point strikes would be last. I don’t have actual execution data to support this—it’s just gut feeling based on what I’ve anecdotally heard from other traders.
One potential issue with filtering for strike multiple is a strike density decrease with lower price of the underlying. The relative difference between one 10-point strike and another generally gets larger going back in time where SPX is valued lower. With SPX at 4000, 10 points is only 0.25%. With SPX at 1500, though, 10 points is 0.67%. I cannot say how significant a concern this is, but it would be 2.5x worse for 25-point strikes. The base strategy is not intended to be directional.
Going back to L70, I no longer need the lower bound with my proposed solution in the second paragraph of Part 6. The program will find the first option that has less than (((mte + 1) * 30 ) + 5) DTE. The extra five along with 30 (two more than the more common 28-day) will cover a 35-day expiration cycle, which happens once per quarter. The option I want will be that or the next-lower DTE option to match. The latter will be checked by the check_second flag.
Rather than nested ifs, I could code as an if-else block per fifth paragraph of Part 4, but I don’t see any real advantage. Additional logic in the else block may dictate that nothing be executed for the current iteration (only 0.4% of rows are used). I would have to include a pass (null) statement or two (as if-elif-else) since if-else forces execution of one branch or the other.
In the second paragraph of Part 4, I said the update_long logic avoids a subsequent match to options on the same date even though the same-date options are not being skipped. That logic is in L134:
![]()
This looks to match strike price and expiration date. Recall the third paragraph here. Once find_short is complete, same-date options are avoided despite the wait_until_next_day flag being circumvented because each strike/expiration combination only appears once per historical date. Is this more or less efficient?
Although I may be wrong due to “mitigating factors” (second-to-last paragraph of Part 4), I would hypothesize matching strike price and expiration date to be less efficient than skipping dates with wait_until_next_day. The latter requires one truth test to compare current_date and historical date whereas update_long’s and statement requires two.
Loose ends be gone!
Categories: Python | Comments (0) | PermalinkBacktester Logic (Part 6)
Posted by Mark on September 6, 2022 at 06:45 | Last modified: June 22, 2022 08:35Today I want to finish ironing out the logic from L70 shown here then continue to analyze that conditional skeleton.
As an example of my proposed solution at the end of Part 5, in 2015 (date 16448) we have options with 94 DTE followed by options with 66 DTE. Both pass L70, which means the latter is what I want. I can add a Boolean flag check_second that starts out as False. Once int(float(stats[2])) no longer equals L_dte_orig (see key), the flag gets changed to True. If this passes L70 then find_long continues in this DTE. If it fails L70, then change control_flag to find_short and continue (to the next iteration) without setting wait_until_next_day to True.
In addition to the 60 – 95 DTE range, I am also interested in studying longer-dated time spreads despite potential issues with slippage. Examples include 90 – 125, 120 – 155, and 150 – 185 DTE. Live trading is the best way to understand slippage. Unfortunately, I can’t go back and live trade in previous years. Common wisdom suggests slippage will be lower with higher volume and open interest, but the data files don’t allow me to test this. I could plot volume and open interest over time, but this may be a waste of time since I have no way to know how that might translate to slippage.
Another thing that may limit my ability to backtest longer-dated options is historical availability. Over the years, more expirations and more strike prices have come available coincident [I suspect] with higher-volume option trading. In 2015, 168 DTE is available followed by 105 DTE, which means I can’t do a time spread one month wide. Things change in 2020. In early Jan 2015, monthly expirations appear for the first four months. In early Jan 2020, monthly expirations appear for the first six months. This expresses my concern despite being anecdotal observation.
One thing I don’t see in the conditional skeleton is a continue statement at the bottom. Whether or not the backtester identifies the current row as the long option, it can then advance to the next iteration (row). Without a continue statement, the program will go on to unnecessarily evaluate control_flag three more times before advancing. “Continue” should conclude the first three branches. Completing the block, the last branch doesn’t need a continue statement as advancing to the next iteration will automatically take place.*
I will press forward next time.
*—Actually, I did remember this. The Atom text editor features folding to hide blocks of code as described
here. With “continue” being the last line of the previously indented blocks, they were hidden.
Backtester Logic (Part 5)
Posted by Mark on August 29, 2022 at 07:14 | Last modified: June 22, 2022 08:34Today I continue to dissect the conditional skeleton of the find_long branch shown near the bottom of Part 4.
L70 – L72 includes eight data type conversions. Early on, I was frustrated with unnecessary decimal output. To fix this, I tried converting applicable fields to data type ‘int'[eger] and some resulted in an error. Doing int(float()) was a successful workaround. I should revisit to see if the readability of output is improved enough to justify the added processing. For curiosity’s sake, I can add a timer to the program and check speed.
L70 filters options by DTE. I can make this more readable by creating two variables for lower and upper bounds followed by one if statement that calls for the variable to fall in between.
As mentioned above, I could add a timer to the program to see if this helps, but I don’t want to get bogged down with repetitive time measurements. If the backtester works, then I’m fine whether it takes 10 minutes 34 seconds or 12 minutes 28 seconds. Either way, I’ll be happy to get the results and spend the bulk of my efforts analyzing those.
Before the program calls for iterating through the data files, I have:
> mte = int(input(‘Enter minimum (>= 2) months (1 mo = 30 days) to long option expiration: ‘))
Suppose I enter 2. At L70, the backtester will search for > 2 * 30 = 60 DTE. This is clear as the lower bound.
The upper bound is more complex because every quarter we get five weeks between consecutive expiration months rather than four. 92 DTE will meet the criteria and be correct only when 92 – 28 = 64 DTE does not follow in the current expiration. Data files are organized from highest to lowest DTE (see Part 1). With the goal to maximize efficiency by having the backtester going through the files once, I can’t have it iterating down and then having to go back up if what it finds below is not a match.
Thankfully, it doesn’t have to be that complicated.
The solution is to select and encode the first passing option but wait to leave the find_long branch until DTE changes. The program can then test whether the subsequent DTE also meets the criteria. If so, dump the values from the former and search for a new match. Otherwise, use the former. Switch to the find_short branch once this is all done.
If the first option meeting the criteria is less than 60 + 28 = 88 DTE, then no circumstance exists where the next DTE to appear will pass. In that case, no second check is even needed.
I will continue next time.
Categories: Python | Comments (0) | PermalinkLessons on Twinx()
Posted by Mark on August 26, 2022 at 06:48 | Last modified: May 17, 2022 15:57I spent the whole day yesterday trying to figure out why I got overlapping axis labels on a secondary axis for my graph. I want to document what I’ve learned about the twinx() function.
Let’s start by creating a df:
Now, I’m going to add two lines. Spread price will be in red and SPX price will be in blue:
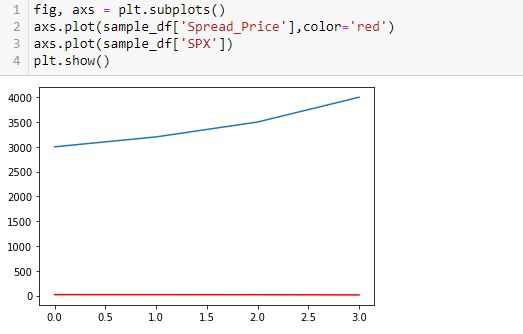
This doesn’t work very well. In order for the y-axis to accommodate both, the spread price looks horizontal since its changes are so small relative to the magnitude of SPX price.
To fix this, I will create a secondary y-axis on the right side:
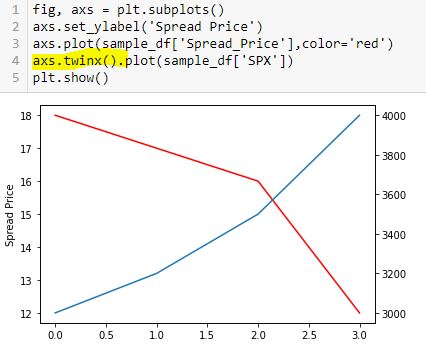
Now, I label the right y-axis:
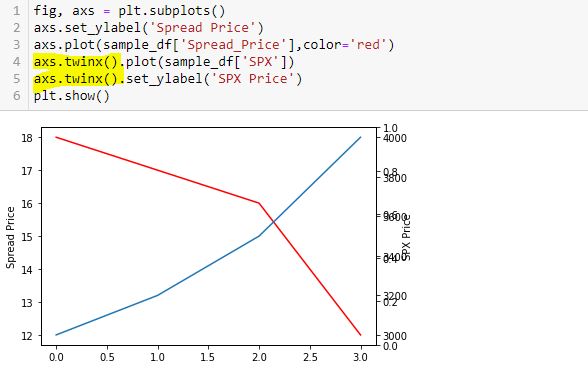
Whoa! This generates an overlapping set of y-axis labels on the right going from 0.0 to 1.0. What happened?
Here is a correct way to do this:
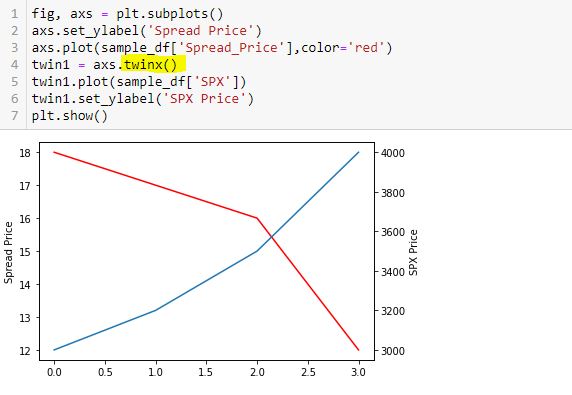
Thinking substitution is what confused me. I saw this solution online but got confused because I interpreted L5-L6 as substitution from L4 and had trouble wrapping my mind around it. I therefore chose to do it the long way:
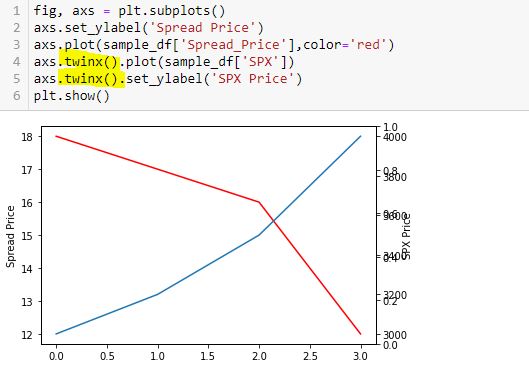
This is not the way Python works. Python is not algebra.
Had I questioned this [which I didn’t], I could have verified with a truth test:
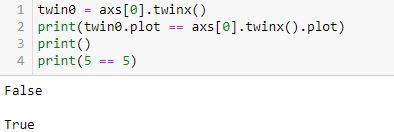
L2 is False (unlike L4, which is obviously True).
twinx() creates a new y-axis each time it is called. Calling more than two can lead to the overlapping labels.
Furthermore, a function or method like twinx gets called each time the function/method name is followed by (). When you see “name()”, you are seeing a function/method call. This is not something I ever read in documentation or in Python articles. To me, this most definitely is not obvious. The third and fourth code snippet above include twinx() once and twice, respectively. This is why the fourth has an overlapping y-axis. The fifth code snippet has twinx() just once: no problem.
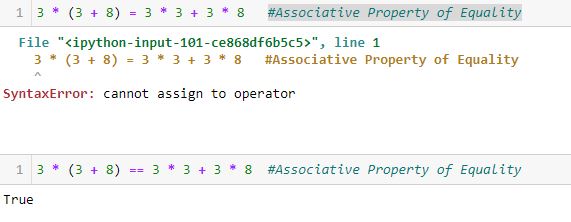
Anytime I see a single equals sign, it might help to think “is assigned to.” The variable will retain said value until something dictates otherwise. No substitution is taking place and no properties of equality necessarily apply.
Once more for emphasis:
Backtester Logic (Part 4)
Posted by Mark on August 23, 2022 at 06:34 | Last modified: June 22, 2022 08:34I left off tracing the logic of current_date through the backtesting program to better understand its mechanics. The question at hand: how much of a problem is it that current_date is not assigned in the find_short branch?
Assignment of control_flag (see key) to update_long just before the second conditional block of find_short concludes with a continue statement is our savior. Although rows with the same historical date will not be skipped, the update_long logic prevents any of them from being encoded. Unfortunately, while acceptable as written, this may not be as efficient as using current_date. I will discuss both of these factors later.
The update_long branch is relatively brief, but it does assign historical date to current_date thereby allowing the wait_until_next_day flag to work properly.
Like find_short, the update_short branch begins by checking to see if historical date differs from trade_date. I coded for an exception to be raised in this case because it should only occur when one leg of the spread has not been detected—preumably due to a flawed (incomplete) data file. Also like find_short, update_short has two conditional blocks. At the end of the second block, wait_until_next_day is set to True. This can work because current_date was updated (prevous paragraph).
I have given some thought as to whether the two if blocks can be written as if-elif or if-else. In order to answer this, I need to take a closer look at the conditionals.
Here is the conditional skeleton of the find_long branch:

Right off the bat, I see that L71 is duplicated in L72. I’ll remove one.
Going from most to least restrictive may be the most efficient way to do these nested conditionals. In the fourth-to-last paragraph here, I discussed usage of only 0.4% total rows in the data file. Consider the following hypothetical example:
- Data file has 1,000 rows of which 4 (0.4%) will ultimately be used.
- 50, 100, and 200 rows meet the A, B, and C criteria, respectively.
- Compare nested conditionals “if A then if B then if C…” (Case 1) vs. “If C then if B then if A…” (Case 2).
- All 1,000 rows get evaluated by each Case.
- Case 1 leaves only 50 rows to be evaluated after the first truth test vs. 200 for Case 2 and Case 2 likely has more rows still left to be evaluated going into the final truth test.
- Case 1 is more efficient.
All else being equal, this makes sense to me.
Other mitigating factors may exist, though, like number of variables involved in the evaluation, data types, etc. In trying to apply this rationale to the code snippet above, I may be overthinking something that I can’t fully understand at this point in my Python journey.
I will continue next time.
Categories: Python | Comments (0) | PermalinkBacktester Logic (Part 3)
Posted by Mark on August 15, 2022 at 06:49 | Last modified: June 22, 2022 08:34I included a code snippet in Part 2 to explain how the wait_until_next_day flag is used in the early stages of the backtesting program. I mentioned that once the short option is addressed (either via finding long/short branches or updating long/short branches), the program should skip ahead in the data file to the next historical date.* This begs the question as to where in the program current_date gets assigned. Today I will take a closer look to better understand this.
The find_long branch (see control_flag here) assigns a value to trade_date. Do I need this in addition to current_date? I created trade_date to mark trade entry dates and on trade entry dates, the two are indeed identical. I could possibly use just current_date, eliminate trade_date, and add some lines to do right here with the former what I ultimately do with the latter. This is worthy of consideration and would eliminate what may be problematic below.
The find_short branch has two conditional blocks—the first of which checks to see if historical date differs from trade_date. This could only occur if one leg of the spread is found, which implies a flaw in the data file. In this case, trade_date is added to missing_s_s_p_dict, control_flag (branch) is changed to find_long, and a continue statement returns the program to the top of the loop where next iteration (row of data file) begins. The process of finding a new trade commences immediately because wait_until_next_day remains False.
The other conditional block in the find_short branch includes a check to make sure historical date equals trade_date. This seems redundant since the first conditional block establishes them to be different. I could probably do one if-elif block instead of two if blocks since the logic surrounding date is mutually exclusive. This may or may not be more efficient, but this second conditional block also has some additional logic designed to locate the short option—additional logic that, as above, could pose a problem if the data file is flawed.
At the end of this second conditional block, wait_until_next_day is set to True but current_date is not assigned. This seems problematic because L66 (see Part 2) will be bypassed, wait_until_next_day will be reset to False, and the flag will basically fail as rows with the same historical date will be subsequently evaluated rather than skipped. Remember, for the sake of efficiency, every trading day should include either finding or updating: not both. How much does this matter?
I will continue next time.
*—Historical date is a column of the data file corresponding to a particular trading day.
Backtester Logic (Part 2)
Posted by Mark on August 9, 2022 at 07:11 | Last modified: June 22, 2022 08:34Last time, I discussed a plan to iterate through data files in [what I think is] an efficient manner by encoding elements only when proper criteria are met. Today I will continue discussing general mechanics of the backtesting program.
While the logic for trade selection depends on strategy details, the overall approach is dictated by the data files. The program should ideally go through the data files just once. Since the files are primarily sorted by historical date and secondarily by DTE, in going from top to bottom the backtester needs to progress through trades from beginning to end and through positions from highest to lowest DTE. This means addressing the long leg of a time spread first as it has a higher DTE.
Finding the long and short options are separate tasks from updating long and short options once selected. When finding, the backtester needs to follow trade entry guidelines. When updating, the backtester needs to locate previously-selected options and evaluate exit criteria to determine whether the trade will continue. I therefore have four branches of program flow: find_long, find_short, update_long, and update_short.
Going back to my post on modular programming, I could conceivably create functions out of the four branches of program flow. Two out of these four code snippets are executed on each historical date because opening and updating a trade are mutually exclusive. I do not see a reason to make functions for this since the program lacks repetitive code.*
Whether finding or updating, once the short option has been addressed the backtester can move forward with calculating position parameters and printing to the results file. For example, in order to calculate P_price = L_price – S_price (see key here), the program needs to complete the find_long / find_short or update_long / update_short branches since the position is a sum of two parts. One row will then be printed to the results file showing trade_status (reviewed in previous link), parameters, and trade statistics.
Since every trading day involves either finding or updating, once the short option has been addressed any remaining rows in the data file with the same historical date may be skipped. For that purpose, I added the wait_until_next_day flag. This is initially set to False and gets toggled to True as needed. Near the beginning of the program, I have:
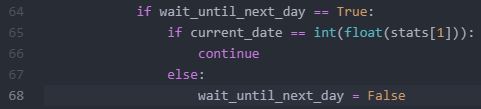
If the flag is True, then the continue statement will return the program to the top where the next iteration (row of the .csv file) begins. This will repeat until the date has advanced at which point the flag will be reset to False.
To complete our understanding of this matter, I need to analyze where current_date is assigned.
I will continue with that next time.
*—Resetting variables is the one exception I still need to discuss.
Backtester Logic (Part 1)
Posted by Mark on August 1, 2022 at 07:26 | Last modified: June 22, 2022 08:34Now that I have gone over the modules and variables used by the backtester, I will discuss processing of data files.
My partner (second paragraph here) has done some preprocessing by removing rows pertaining to calls, weekly options, deepest ITM and deepest OTM puts, and by removing other unused columns. Each row is a quote for one option with greeks and IV. I tend to forget that I am not looking at complete data files.
As the backtester scans down rows, option quotes are processed from chronologically ordered dates. Each date is organized from highest to lowest DTE, and each DTE is organized from lowest to highest strike price.
My partner had given some thought to building a database but decided to stick with the .csv files. Although I did take some DataCamp mini-courses on databases and SQL, I feel this is mostly over my head. I trust his judgment.
I believe the program will be most efficient (fastest) if it collects all necessary data from each row in a single pass. I can imagine other approaches that would require multiple runs through the data files (or portions therein). As backtester development progresses (e.g. overlapping positions), I will probably have to give this further thought.
The first row and column of the .csv file are not used. The backtester iterates down the rows and encodes data from respective columns when necessary. The first column is never called. Dealing with the first row—a string header with no numbers—requires an explicit bypass. It could raise an exception since the program evaluates numbers. The bypass is accomplished by the first_bar flag (initially set to True) and an outer loop condition:
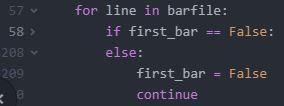
The first iteration will set the flag to False and skip everything between L58 and L208. The bulk of the program will then apply to the second iteration and beyond.
To maximize efficiency, the backtester should encode as little as possible because most rows are extraneous. Backtesting a time spread strategy that is always in the market with nonoverlapping positions requires monitoring 2 options/day * ~252 trading days/year = 504 rows. My 2015 data file has ~120,000 rows, which means just over 0.4% of the rows are needed.
I will therefore avoid encoding option price, IV, and greeks data unless all criteria are met to identify needed rows.
A row is needed if it has a target strike price and expiration month on a particular date but once again, in the interest of efficiency the backtester need not encode three elements for every row. It can first encode and evaluate the date, then encode and evaluate the expiration month, and finally encode and evaluate the strike price. Each piece of information need be encoded only if the previous is a match. Nested loops seem like a natural fit.
I will continue next time.
Categories: Python | Comments (0) | Permalink